

面向 LLM 与 Agent 的文档智能基础设施
AI 需要可信的数据来源,而不是原始文档
TextIn 将杂乱、非结构化的文档转化为干净、一致、可用于 AI 的知识
TextIn 将杂乱、非结构化的文档转化为干净、一致、可用于 AI 的知识
API文档
私有化部署
查看价格
生态集成
全球 1,000 + 领先企业的选择
已处理多种类型的文档
1,000,000,000 +页
从原始文档到结构化的
AI 可用知识
AI 可用知识
统一的 Document AI 基础设施,支撑 Agent、RAG、与企业级 AI 应用








原始文档





TextIn xParse
AI 可用知识
超越 OCR
对大模型更友好的文档解析
对大模型更友好的文档解析
高精度文档解析引擎 助力大模型精确理解文档内容
将任意版式的文档拆解为语义完整的段落,并按阅读顺序还原,更加适配大模型
行业领先的表格识别能力,轻松解决合并单元格、跨页表格、无线表格等识别难题
标题、公式、手写体、印章、页眉页脚、跨页段落也能正确识别
无缝集成TextIn平台中的图像处理能力,文档带水印、图片有弯曲,都能搞定
还能捕捉更多版面元素间的语义关系,让大模型更加读懂文档


让文档对所有 AI 都可用
AI 只有在理解企业文档时才能发挥更大价值
TextIn 将原始文件转化为可信知识,服务所有 AI 工作流
TextIn 将原始文件转化为可信知识,服务所有 AI 工作流
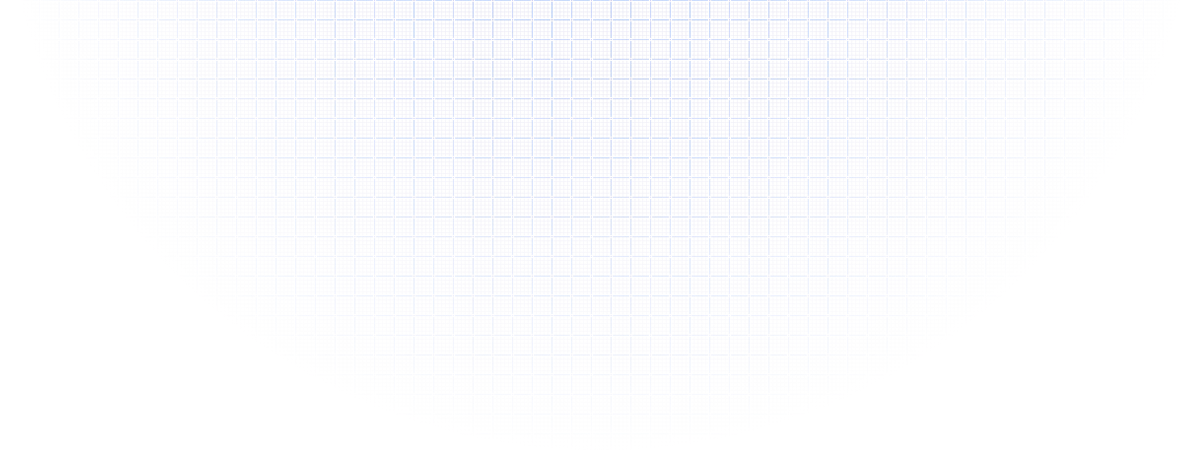
plan
execute
AGENT ERAME
raw file
search_chunk
search_entity
clean data
xParse
fixed table
利用内置的 OCR、分 chunk 与带审计治理的文档处理工作流,构建稳定持续的 AI Agents
TextIn 打通了我们存放在 S3 的文档与内部部署的 LLM,通过高质量的表格解析与元数据还原,我们在几周内就完成了智能体系统的规模化。
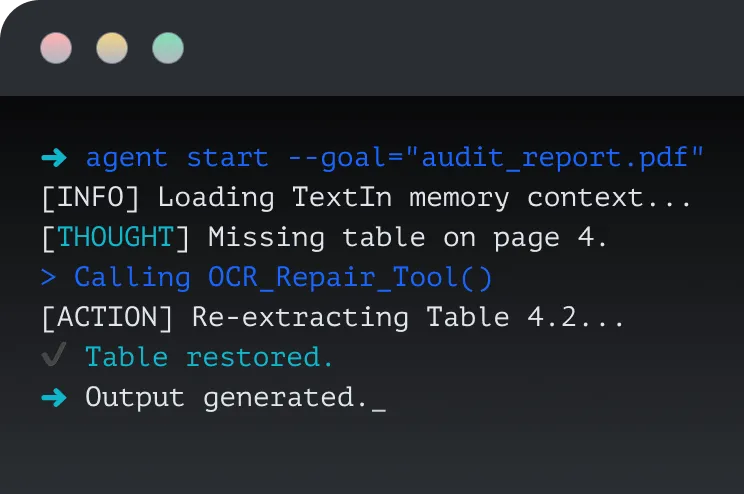
PDF
Img
DATA SOURCE
parse
chunk
xParse
VECTOR STORE
可扩展的企业级智能:一个 RAG 工作流即可适配业务上的多种类型文档
TextIn xParse 能将复杂的监管、临床与研究文献都转化为统一的知识层,让我们成功构建了高质量的医学医药知识库。
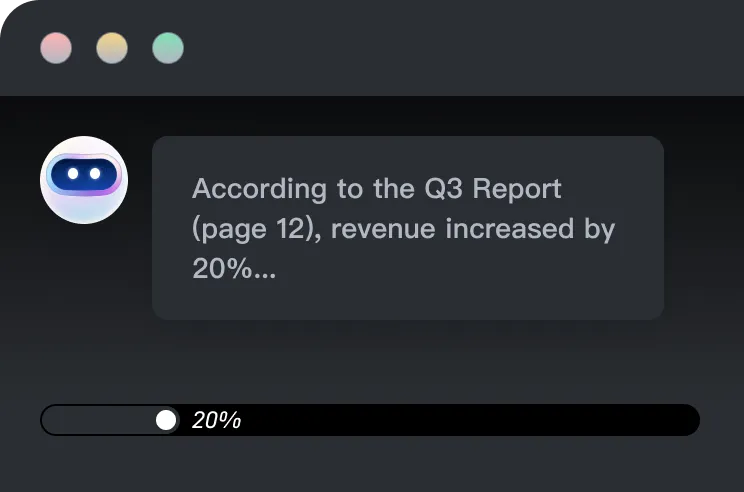
User A
User B
Upload Page
index
LLMs
LLM Runtime
xParse
normalize
parse
semantic chunk
Read & Chat Page
将任何文档转化为对 LLM 和 Agent 友好的格式
方便各类 AI 应用的开发与使用
方便各类 AI 应用的开发与使用
不管用户上传的什么文件都可以交给 xParse 处理,对于我们构建问答、摘要、翻译、改写等场景都很好用。
User A
User B
Reviewer
Apps
File
class A
class B
class C
...
Schema
A
B
C
...
parse
extract
xParse
K-Vs
...
Validation
智能数据提取管线:从规则走向 LLM 驱动的抽取架构
我们成功整合先进的 LLM 抽取技术,在财务报销与审计流程中实现 90%+ 准确率,并大幅减少了规则维护的难度。
统一、可扩展的文档理解层
即插即用、可切换、面向未来
一次集成即可支持主流解析引擎——现在与未来皆可用
一次集成即可支持主流解析引擎——现在与未来皆可用
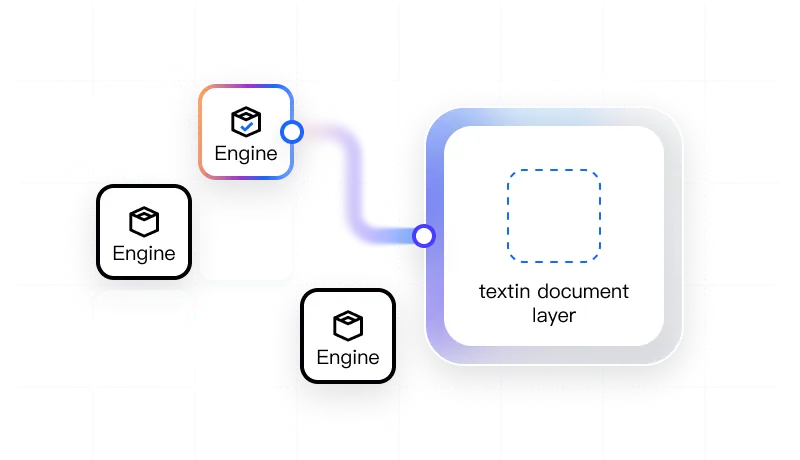
多引擎切换
支持 LLM、OCR 引擎与开源解析器。
一次集成,解锁全部主流引擎,最佳准确率。

图像预处理能力
更干净的输入才能有更好的输出
图像预处理,将低质量文档变得更清晰。

面向未来的插件化架构
无需改变工作流即可新增或替换引擎。
让你的文档理解能力永不过时。
每一类企业文档都能被 LLM 精准理解
从扫描件和超长文档,到复杂表格和图表——全部输出为统一的、LLM 友好的格式
PO
供应链
SLA
企业运营
KYC
金融
MoM
企业运营
RR
行业研究
RCPT
金融
NDA
法务
LA
医疗
CFS
金融
P&L
金融
Manual
客户服务
BOL
供应链
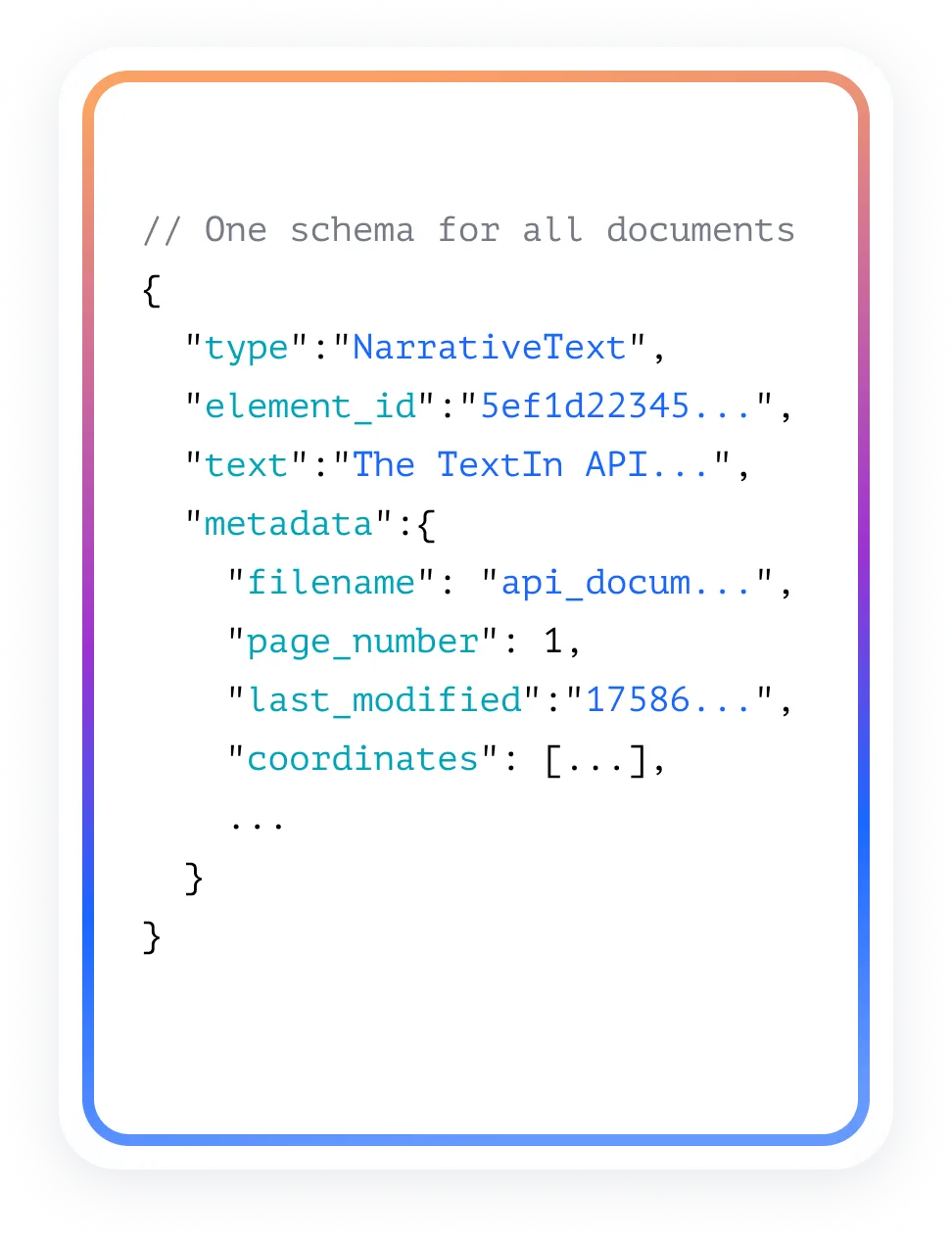
统一的解析 →
结构化层
全自动的 OCR、清洗、解析与分块流程,让每次输出都能稳定一致。
16+
文档格式
PDF、扫描件、表格、PPT、邮件、截图等——支持 16+ 种企业文档格式。
云端 &
本地数据
连接 OSS、S3、FTP、NAS 与本地文件系统,适配任意企业文档工作流。
分分钟上线企业级 AI 工作流
无需脚本、无需自建流程
今天上传文档,今天上线生产级工作流
今天上传文档,今天上线生产级工作流
旧方式:慢、零散、难扩展
 脚本、规则、定时任务到处都是
脚本、规则、定时任务到处都是 OCR、解析、清洗、分块分散在多个工具中
OCR、解析、清洗、分块分散在多个工具中 要持续维护胶水代码
要持续维护胶水代码新方式:快、统一、生产级
 从原始文档到业务可用的输出能一站式管理
从原始文档到业务可用的输出能一站式管理 零脚本/定时任务维护
零脚本/定时任务维护 一套 SDK 即可上线 RAG 或智能体
一套 SDK 即可上线 RAG 或智能体几行代码,分钟级上线
上传 → 自动结构化 → 立即驱动业务工作流
Python
持续更新,始终同步
TextIn 能监测数据源的变化,只解析新增内容
让你的知识与工作流自动保持最新
updated
chunks
#
0
1
2
3
4
5
6
7
8
9
关键任务的可信底座
TextIn 符合银行级安全标准,提供企业级
Document AI 所需的扩展性、可靠性与确定性
Document AI 所需的扩展性、可靠性与确定性
安全与合规
SOC2 Type II / ISO 27001
AES-256 加密
支持私有化部署
确定性输出
结果可重复、可预测
减少 LLM 幻觉
适用于高风险场景
大规模处理
日处理 1,000 万+ 页
应对流量峰值的弹性扩展
99.99% API 可用性
全链路可追溯
页面、段落、字符多级溯源
精确的文本内容定位
每次转换可审计、可验证
为什么开发者选择我们?
构建可靠、精准的 AI 文档系统需要的,我们都有
挣扎在手搓脚本中
成千上万份文档、无穷无尽的边界情况、零可见性。
RAG 性能提升
更干净的分块、更精准的坐标、更一致的元数据,意味着更低幻觉、更高召回。
<2%
幻觉率
99%
表格准确率
2x
召回率
生态即插即用
可直接接入现有 RAG 技术栈。
兼容 Hi Agent、Dify、RagFlow、Langchain、Milvus、Pinecone、Qdrant、pgvector。
开发者友好
无需微调、无需管道。
一套简单 API 即可获得干净分块。

来自合作伙伴的认可
"我们自研过一段时间表格解析,但精度远没有 TextIn 高,现在综合调用后,成本和效果都有了更好的保障。"
技术负责人
某财经数据库技术中台
"原先手工处理时,我每天都要大半天做机械工作,接入 TextIn 之后,现在只要半小时来核对就行了,真的快了很多!"
数据运营主管
某货运公司数据组
"知识库离不开文档解析,我们对比了很多家的产品,最后发现 TextIn 的解析是最让我们满意的。"
产品负责人
某 AI 知识库厂商
"TextIn 文档解析最打动我们的就是表格识别,各种复杂表格都能稳定输出。"
工程师
某大型制造业集团研究院
"TextIn 在解析长文档时,速度特别快。我们内部搭了很高配置的集群,也达不到这个速度。对于实时问答类场景,TextIn 真是在用户体验上帮大忙了"
技术经理
某融资租赁公司
"早期我们用开源的 PDF 解析组件搭了一个问答产品,结果有很多用户吐槽。后来经过对比,用 TextIn 来做解析,用户的负面反馈就明显变少了。"
研发负责人
某大模型厂商










