从视觉到语义逻辑:版面分析技术浅析
👀如何理解版面分析(DLA)技术在产业或生活产生的作用?
想象一下,在一家电商巨头的仓库里,每天都有海量的物流单据需要处理。过去,员工们需要手动录入信息,费时费力,而且很难避免疏漏错误。在文档版面分析技术投入应用后,机器能自动识别单据上的文字和布局,快速提取关键信息。这背后,是DLA技术从实验室走向现实的典型场景。
文档版面分析(DLA)的研究始于20世纪90年代,最初主要关注简单文档结构,主要使用基于规则的方法或统计技术,融入特征提取和模式识别,使得系统能初步理解文字在页面上的相对位置和关系。
进入21世纪后,DLA开始引入特征工程和机器学习,将任务视为基于像素的语义分割。2015年以来,深度学习技术,尤其是卷积神经网络(CNN)和Transformer,主导了该领域的发展,利用视觉特征分析物理布局,让机器能够像人类一样“看懂”文档的结构,识别文字、表格和图片的位置,极大地提高了识别精度。DLA不再局限于识别静态文本,它还可以处理各种复杂的文档类型,比如带有图表、图片和多栏排版的专业期刊或报告。此外,图卷积网络(GCN)被用于建模文档组件之间的关系,增强语义布局分析。基于网格的方法强调保留空间结构的重要性。近年来,自监督预训练在多模态自然语言处理(NLP)中的应用影响了DLA研究,促使模型联合整合文本和视觉布局信息以实现端到端学习。
一个典型的版面分析算法框架和输出如下图所示。
01.物理版面分析
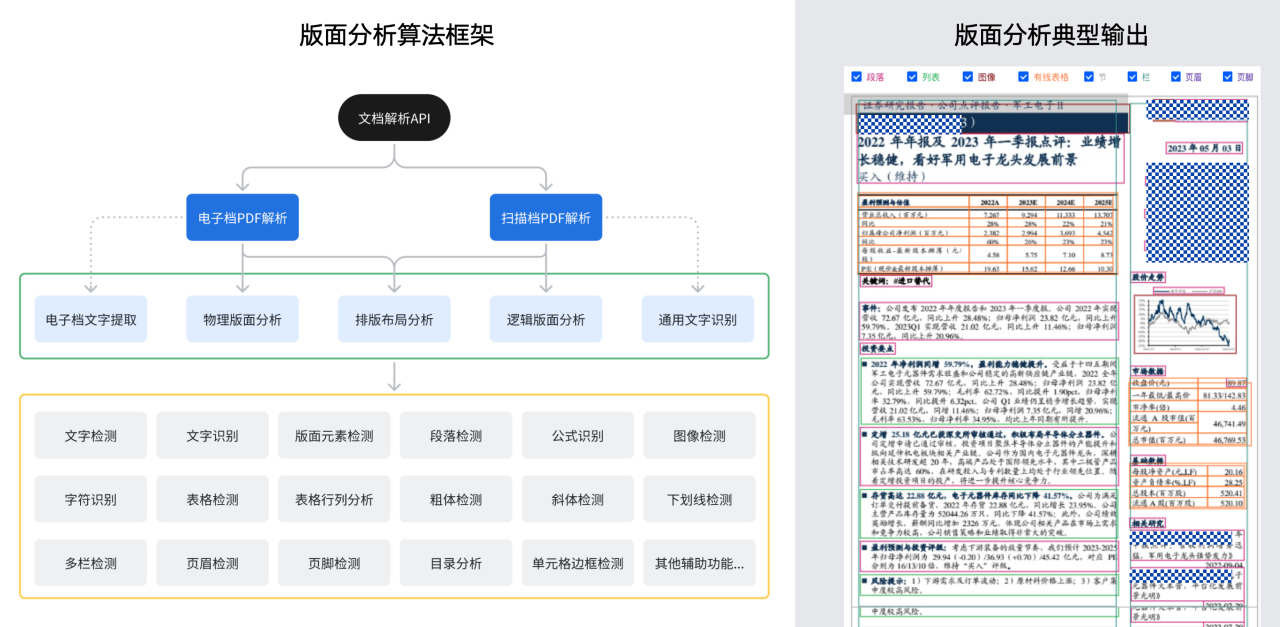
接下来,我们将浅析DLA的各个方法路径,主要分为物理版面分析与逻辑版面分析两大类别。
早期基于深度学习的DLA主要关注利用文档图像的视觉特征分析物理布局。文档被当作图像处理,通过神经网络架构检测和提取文本块、图像和表格等元素,有以下两种典型思路:
聚合:侧重于视觉特征。主要任务是把相关性高的文字聚合到一个区域,比如一个段落,一个表格等等。
布局:选用目标检测任务进行建模,使用基于回归的单阶段检测模型进行拟合,从而获得文档中各种各样的布局方式。

基于CNN的方法
卷积神经网络(CNN)的引入显著提升了DLA的能力。最初为图像中物体检测设计的模型被成功应用于页面分割和布局识别任务,例如R-CNN、Fast R-CNN及Mask R卷积神经网络(CNN)的引入显著提升了DLA的能力。最初为图像中物体检测设计的模型被成功应用于页面分割和布局识别任务,例如R-CNN、Fast R-CNN及Mask R-CNN等算法,在文本块和表格等页面元素的检测上展现了重要作用[1]。
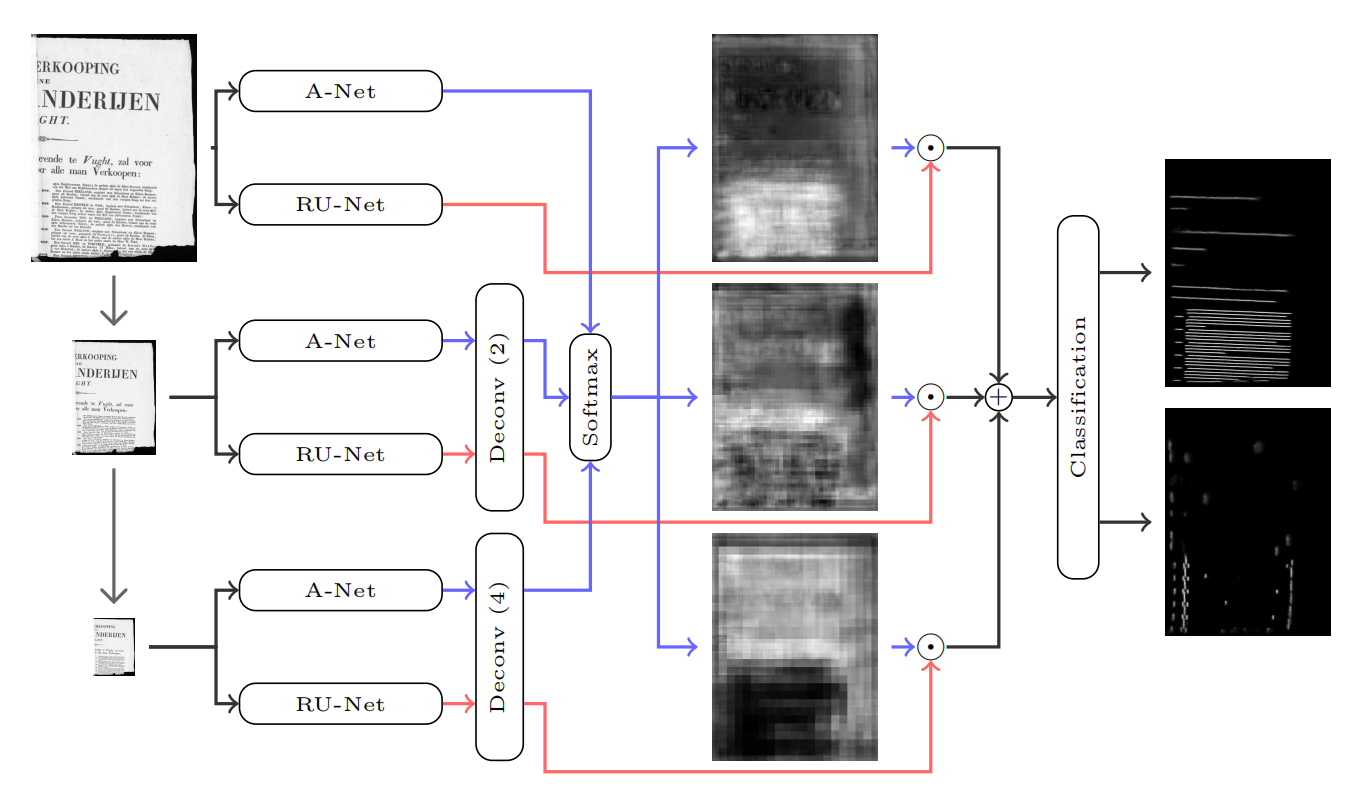
后续的研究专注于优化区域提议过程和技术架构,以增强页面对象检测的效果。为了应对更复杂的布局结构,研究者开发了全卷积网络(FCN)和ARU-Net等新型模型[2][3]。这些改进提高了系统处理多样化布局的灵活性和准确性,进一步推动了DLA技术的发展。
基于Transformer的方法
Transformer模型的最新进展也已应用于文档布局分析(DLA)领域。受BERT启发,BEiT(图像Transformer的双向编码器表示)通过自监督预训练学习强大的图像表示,能够有效提取文档中的标题、段落和表格等全局特征[4]。类似地,文档图像Transformer(DiT)借鉴了Vision Transformer(ViT)的设计,将文档图像分割成小块,以提升布局分析的精度[5]。
尽管这些方法在性能上表现出色,但它们通常计算量较大,并且需要大量的预训练数据。例如,BEiT和DiT都需要经过大规模的数据集训练才能达到最佳效果。后续研究进一步探索了如何利用Transformer架构完成基于文档视觉特征的分类任务,旨在提高处理效率并减少计算资源的需求,使得Transformer在文档分析任务中更加实用和高效[6][7]。
基于图的方法
尽管基于图像的方法显著推动了文档布局分析(DLA)的发展,但这些方法主要依赖于视觉特征,一定程度上限制了对文档语义结构的理解。为了解决这一问题,图卷积网络(GCN)通过建模文档组件之间的关系,增强了对布局的语义分析能力[8]。
例如,Doc-GCN通过优化组件间的语义和上下文关系,提升了整体性能。这种方法不仅考虑了各个组件的视觉特征,还结合了它们之间的相互关系,从而提供更丰富的布局理解[9]。
另一个值得注意的模型是GLAM,它将文档页面表示为一个结构化的图,整合了视觉特征和嵌入的元数据。这种综合处理方式使得GLAM能够更好地捕捉文档内部的复杂结构,实现更精准的布局分析[10]。
基于网格的方法
基于网格的文档分析方法通过网格化表征页面布局来维护空间信息完整性[11]。以BERTGrid为例,该模型在BERT架构基础上实现了空间结构保留机制[12]。进阶的VGT架构则融合Vision Transformer(ViT)与Grid Transformer(GiT)双模块,构建了从字符单元到文本区块的多粒度特征提取体系,从而提供更全面的文档分析能力。然而,由于需要处理大量的网格数据,这类方法普遍存在模型参数规模过大和推理效率偏低的技术瓶颈,对其工程化落地形成一定制约[13]。
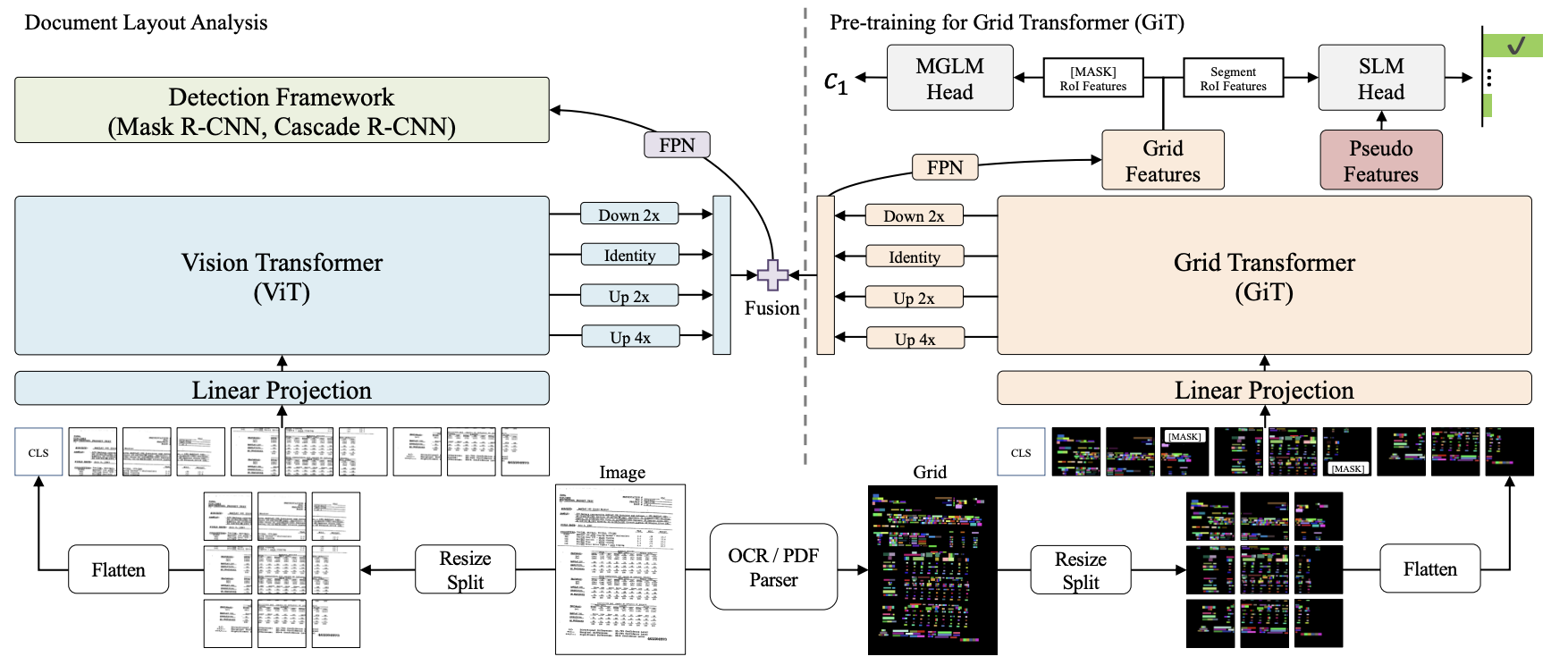
尽管如此,这些方法在特定场景下依然展现出独特的优势,尤其是在需要高精度空间信息保留的任务中。随着技术的不断进步,优化这些模型以提升其效率和实用性,仍然是未来研究方向之一。
02.逻辑版面分析
随着文档分析的复杂性增加,仅依赖物理布局分析已不足以满足需求,结合语义信息的DLA方法成为重要的发展方向。主要任务是把不同的文字块根据语义建模,侧重于语义特征,主要任务是把不同的文字块根据语义建模,根据语义角色对文档元素进行分类,例如标题、图表或页脚。形象地来说,逻辑版面分析能够通过语义的层次关系使文档形成一个树状结构。
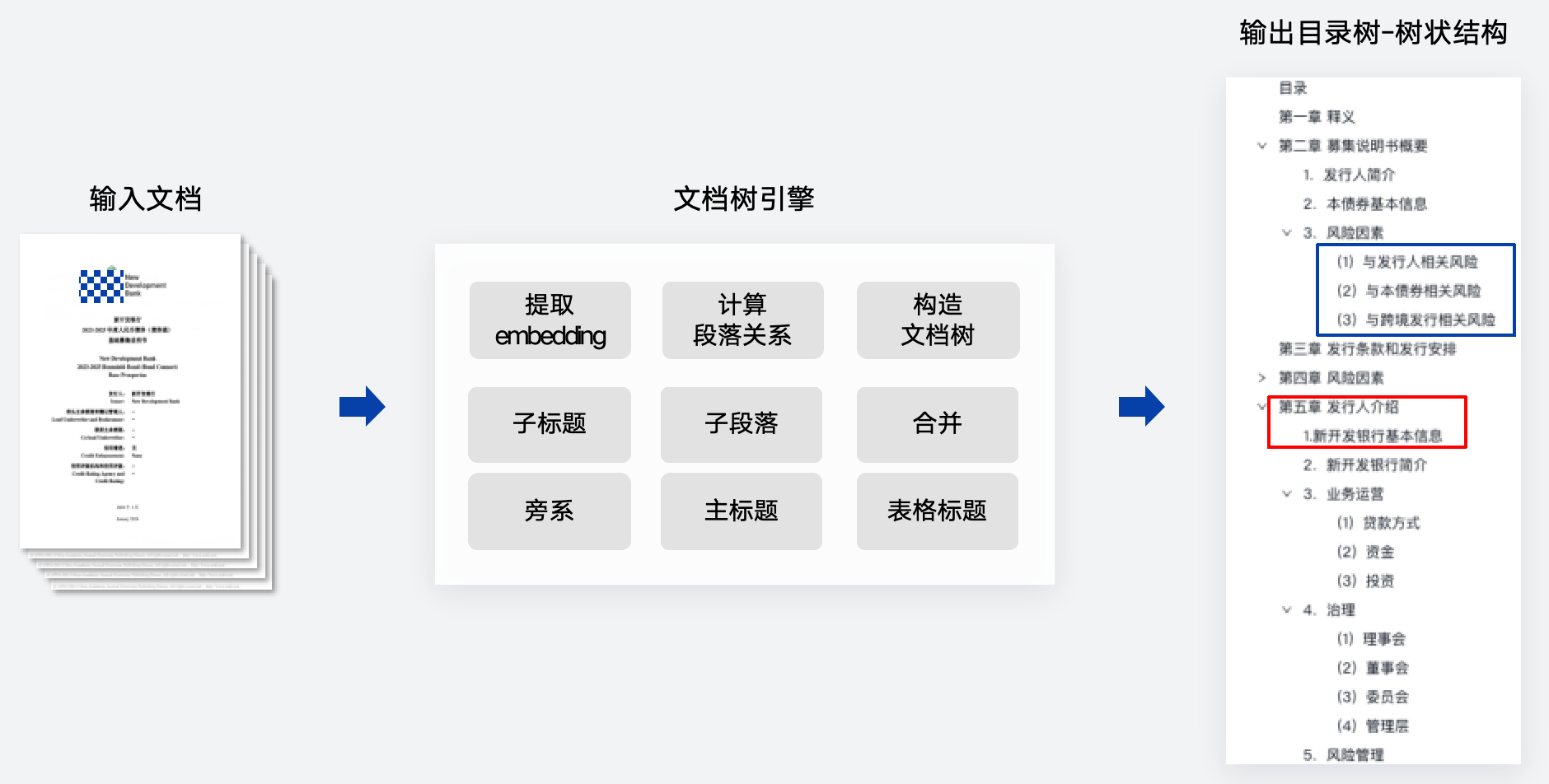
以TextIn算法模型为例,其核心逻辑是通过Transformer架构,预测旁系类型与父子类型,即预测每个段落和上一个段落的关系,分为子标题、子段落、合并、旁系、主标题、表格标题;如果是旁系类型,则再往上找父节点,并判断其层级关系,直到找到最终的父节点,由此形成文档目录的树状结构。
目前,DLA技术已发展为成熟的文档解析工具,在学术与商业场景中落地应用。其中,轻量化部署、随时调用的云端产品成为一项便捷的选择。
💡在线体验文中提及的算法模型:https://cc.co/16YSOT





