TextIn xParse 让AI读懂用户的每份文档
让AI读懂用户的每份文档
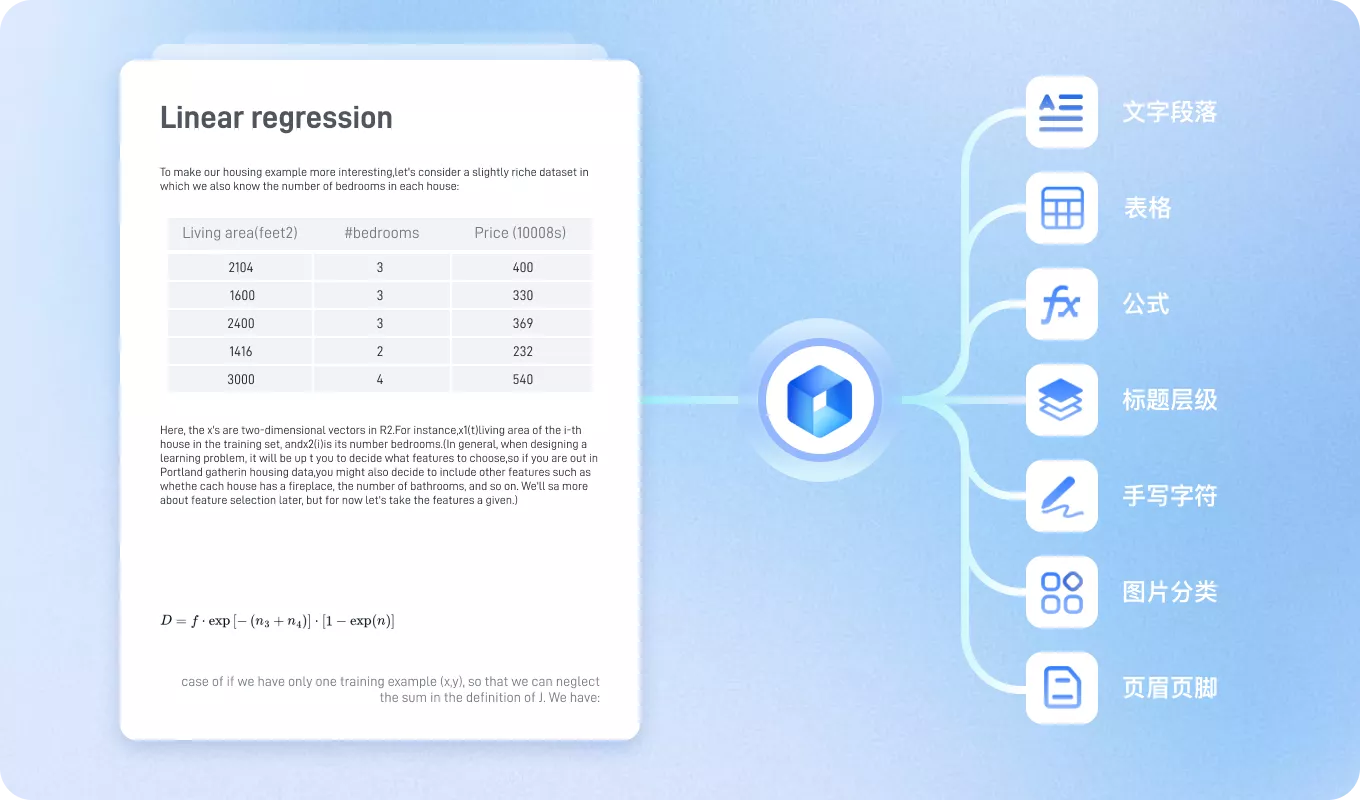
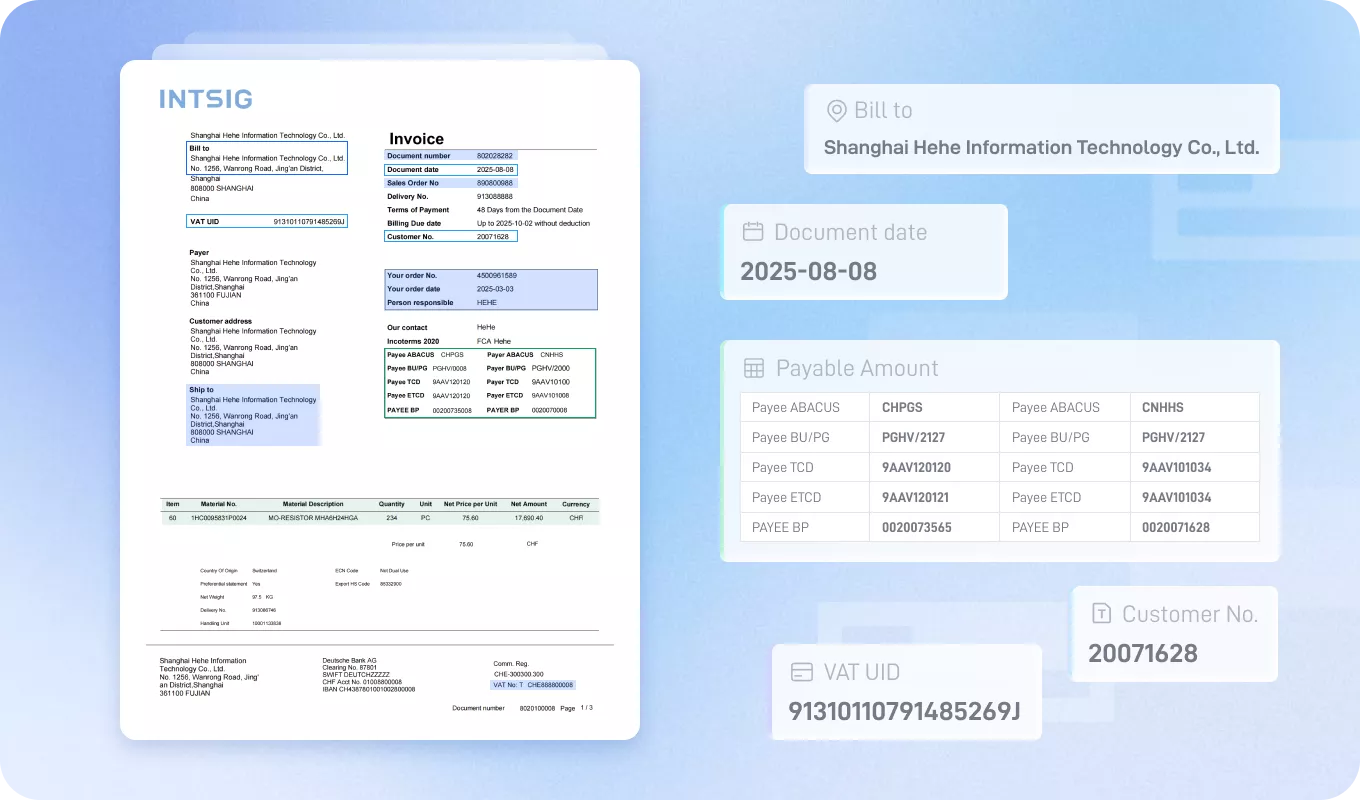
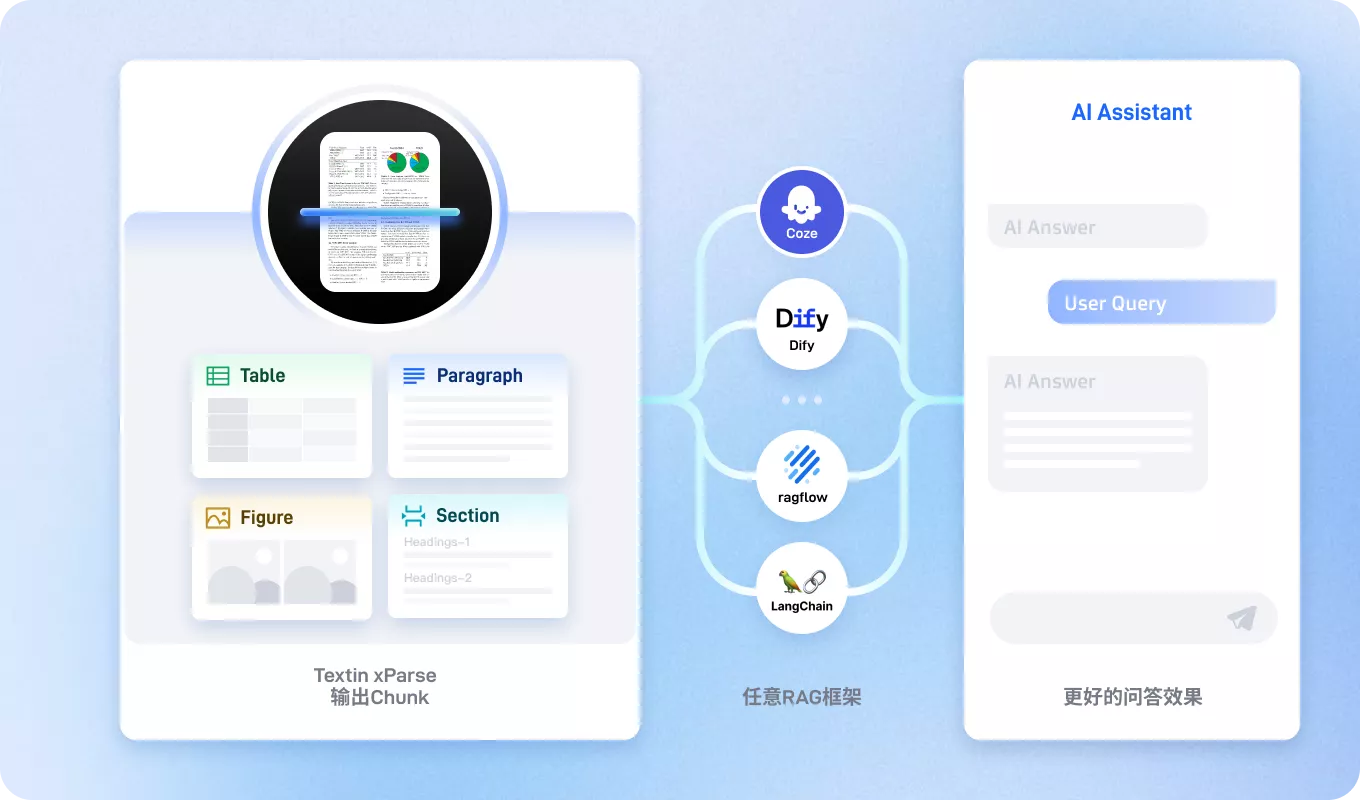
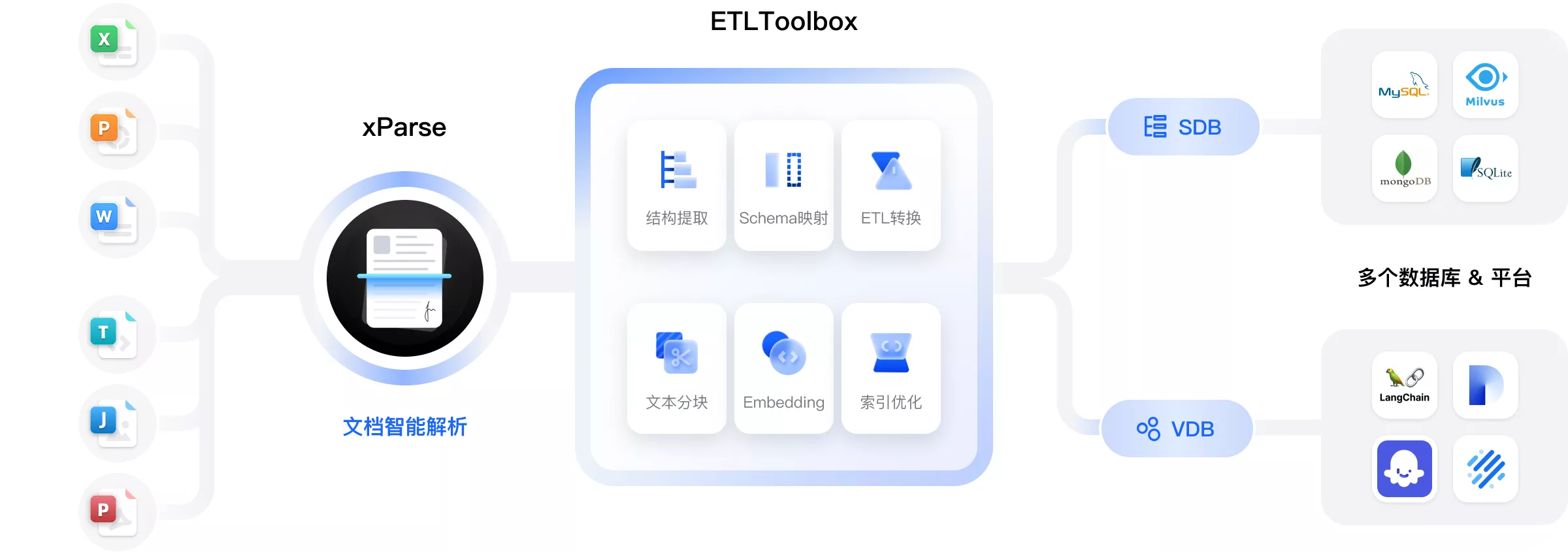
xParse文档解析能将用户上传的PDF、扫描件及图片中的文本、表格、公式等多模态信息进行精准结构化抽取,直接供大模型调用,支撑智能问答、总结与知识检索。
深受全球1000+家领先企业的信赖
累计处理各类文档
1,000,000,000 +页
您的AI应用,是否受困于文档解析质量?

文档格式复杂
PDF、扫描件、图片直接输入大模型,导致关键结构信息丢失

多模态元素解析难
表格、公式、手写体等多模态内容,常规OCR难以精准识别

上下文结构断裂
跨页表格、图文混排无法重建逻辑关联,影响大模型分析能力

处理低效拖累迭代
文档解析缓慢且结果不稳定,严重拖慢应用整体开发与优化周期
从“用户上传文档”到“大模型高质量输入”的升级之路
客户成功案例
来自全球1000+客户的信任与选择

百川智能
挑战
在其AI医疗助手应用中,需要强大的文档解析组件来处理用户上传的泛文档,作为AI理解与对话的基础。
解决方案
xParse多模态解析 + 结构化输出 → 大模型问答
成果
速度
文档处理速度
显著提升
表格识别
表格识别能力增强,顺利
完成医疗报告、论文识别
用户满意度
用户满意度提升,
负面反馈显著减少

深言科技
挑战
“语鲸”信息助手需要高精度解析支持多层级大纲、原文精准定位、多内容聚合等功能。
解决方案
xParse多模态解析 + 结构化输出 → Agent信息聚合
成果
阅读效率
研报中的图表内容可一键
定位,大幅提升阅读效率
用户体验
C端用户体验优化,
问答流畅准确
稳定性
稳定性提升,持续技术
迭代优化,解析稳定可靠

某海外Agent
挑战
用户上传论文、研报,AI总结、翻译、导图生产与问答不准确。
解决方案
xParse多模态解析 → 结构化指标与要点 → 大模型分析报告
成果
60%
PDF处理效率
提升60%
稳定性
稳定性提高,
报错率显著降低
35%
用户满意率
上升35%
百川智能
挑战
在其AI医疗助手应用中,需要强大的文档解析组件来处理用户上传的泛文档,作为AI理解与对话的基础。
解决方案
xParse多模态解析 + 结构化输出 → 大模型问答
成果
速度
文档处理速度
显著提升
表格识别
表格识别能力增强,顺利
完成医疗报告、论文识别
用户满意度
用户满意度提升,
负面反馈显著减少
深言科技
挑战
“语鲸”信息助手需要高精度解析支持多层级大纲、原文精准定位、多内容聚合等功能。
解决方案
xParse多模态解析 + 结构化输出 → Agent信息聚合
成果
阅读效率
研报中的图表内容可一键
定位,大幅提升阅读效率
用户体验
C端用户体验优化,
问答流畅准确
稳定性
稳定性提升,持续技术
迭代优化,解析稳定可靠
某海外Agent
挑战
用户上传论文、研报,AI总结、翻译、导图生产与问答不准确。
解决方案
xParse多模态解析 → 结构化指标与要点 → 大模型分析报告
成果
60%
PDF处理效率
提升60%
稳定性
稳定性提高,
报错率显著降低
35%
用户满意率
上升35%
为何选择xParse?

速度与成本优势
专为解析优化的小模型响应快、部署硬件要求低,支持大规模文档处理,解决大模型解析慢、成本高的问题。

超长文档无损处理
轻松解析上千页长文档,保持结构完整,突破普通开源模型页数限制,适合报告、教材、财报等专业场景。

多模态精准提取
精准解析文本、表格、目录及图片信息,输出结构化数据,直接适配下游AI任务,减少信息丢失与幻觉。

深度理解复杂版面
深度理解跨页、图文混排等复杂版面,还原完整上下文,比常规OCR识别更精准,显著提升AI应用效果。
立即为你的 AI 应用提供高质量文档解析能力
已有 1000+ 客户通过 TextIn 更好地拥抱LLM,进一步放大文档的价值
预约专家演示
查看API文档


