文档解析技术系统梳理:发展脉络、核心架构与趋势思考
伴随企业数字化转型的加速,文档解析已从最初的字符识别工具,发展为支撑智能办公、知识管理和大模型应用的核心技术之一。它的使命不再只是“看懂字”,而是要全面理解文档的结构、语义和逻辑关系,将非结构化数据转化为可计算、可检索、可推理的高价值信息资产。
一、技术背景与发展脉络
文档解析的技术体系经历了三个阶段:
✅第一阶段是基于规则和模板的字符识别,依赖固定版式、统一字体,通过模式匹配实现信息提取;
✅第二阶段引入统计学习方法,如SVM、HMM等,对字符形态和上下文进行概率建模,但在复杂版面、多语种及手写体场景下性能受限;
✅第三阶段也是当前主流阶段,深度学习模型全面接管任务,从图像预处理到语义分析形成端到端解析链路,能够在噪声、形变、跨页等非理想条件下稳定输出结果。
在这一演进过程中,图像识别、自然语言处理、版面结构建模等多学科技术不断融合,推动文档解析由“识别”走向“理解”,为跨行业的自动化和智能化提供坚实的数据输入。
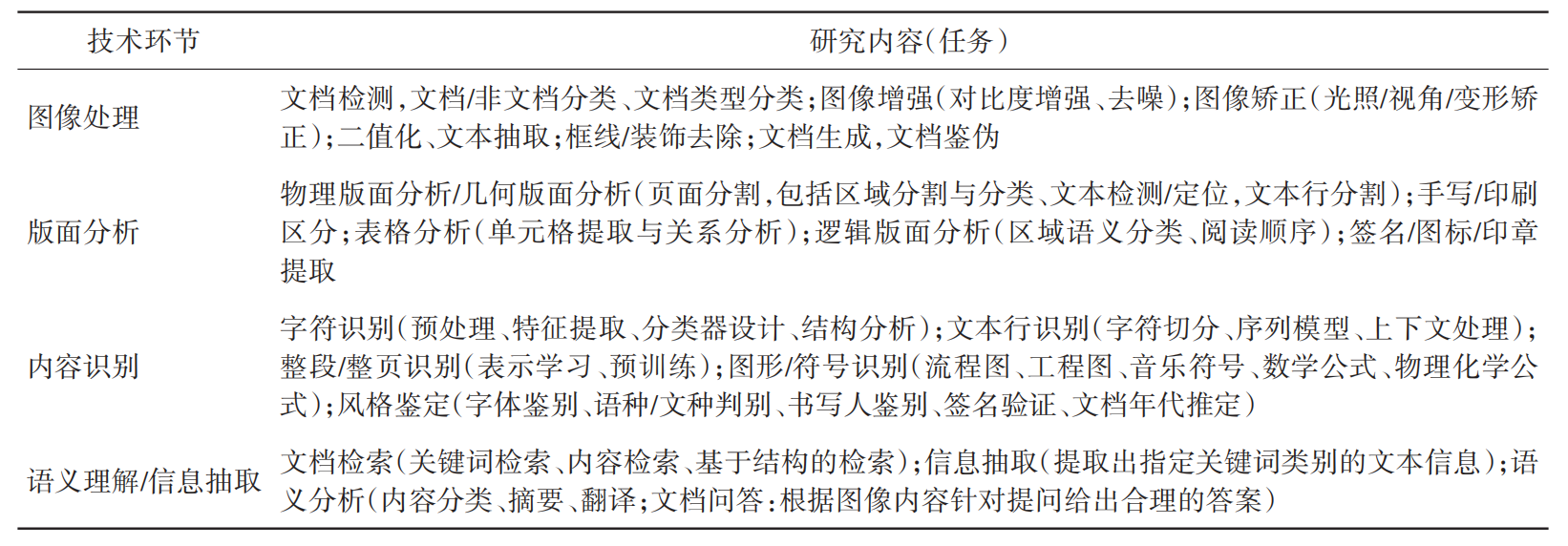
二、文档解析的核心技术环节
1. 文档图像预处理:包括去噪、倾斜矫正、形变校准和分辨率增强。基于深度卷积网络的形变场预测,可以对拍摄角度不规则、纸张卷曲的扫描件进行精准校正,为后续识别打下清晰、标准化的图像基础。
2. 版面分析:从几何分割发展到基于FCN和图神经网络的区域识别与关系建模,不仅能识别段落、标题、页眉页脚、表格等元素,还能理解它们的层级与逻辑关系,为结构化输出提供框架。
3. 文本与符号识别:注意力机制与Transformer结构显著提升了复杂文本、手写体、多语种、公式和流程图的识别准确率,满足科研、教育、工程设计等领域的高精度需求。
4. 语义分析与信息抽取:将识别到的文本映射到特定的知识结构中,提取出实体、关系和属性。结合命名实体识别(NER)、依存句法分析等NLP技术,实现数据的深层理解与业务化建模。
三、LLM时代的文档解析新趋势
大语言模型(LLM)的崛起为文档解析提出了更高要求——不仅要提取准确的文本,还要保留清晰的结构标记和上下文信息,以支持RAG(检索增强生成)等应用。未来的文档解析将更加重视:
结构化输出标准化,如JSON、Markdown、XML,以便机器直接利用。
跨模态解析,将图表、公式、图片与文字整合为统一的数据表达。
实时解析与流式输出,使解析结果可以边生成边被大模型消费。
四、TextIn文档解析的能力矩阵
在多行业落地中,TextIn文档解析展现出强大的精度与适配能力:
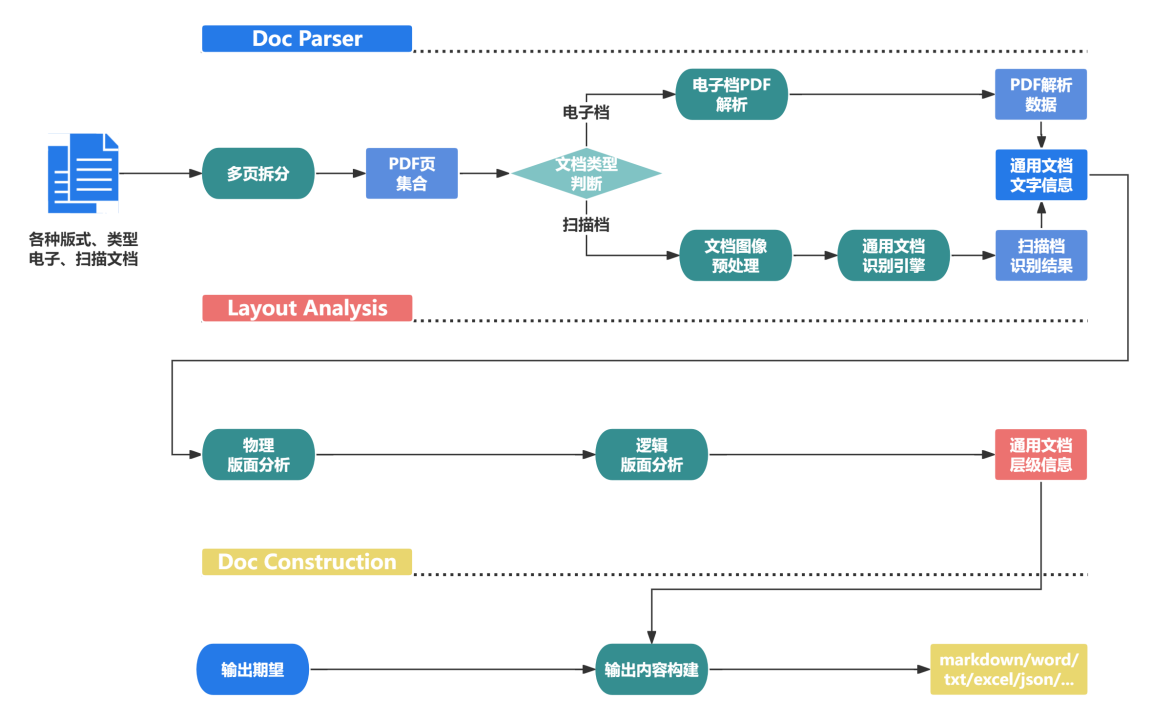
高精度版面分析:精准还原多栏、图文混排、跨页结构,输出多格式结构化数据,确保不同来源文档解析一致性。
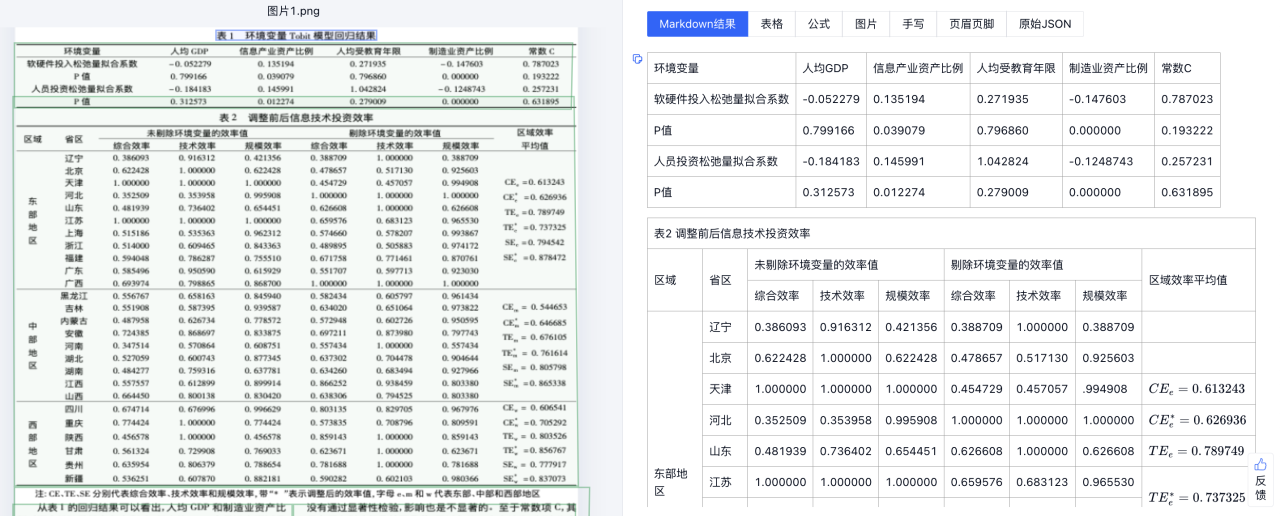
表格解析与结构还原:无损识别无线表、跨页表、合并单元格和密集数据,保持内容与层次的完整性。
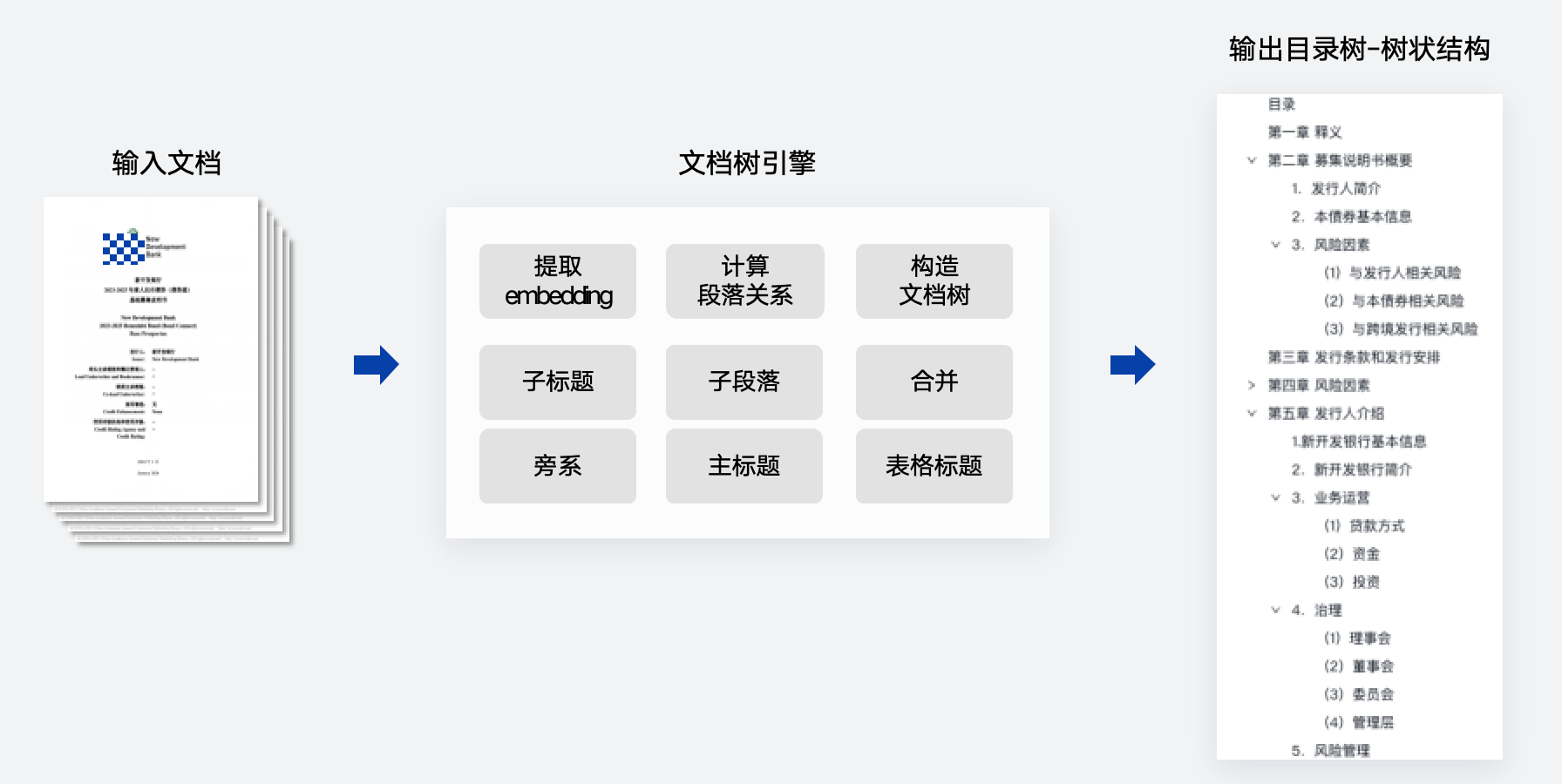
文档树引擎:结合物理版面与语义特征,构建准确的标题层级与目录结构,为知识库建设与大模型输入奠定数据骨架。
五、行业落地价值
金融票据自动化录入、制造业质检报告解析、法律合同结构化存储、政务档案数字化等场景中,文档解析都在加速信息流转、降低人工成本、提升决策效率。它不仅是数据治理的入口,更是企业构建长期数据资产、支撑智能化升级的基础设施。





