告别规则编写,文档内容提取进入零样本智能阶段
在企业的日常运营中,合同、票据、证照、研报、公告等非结构化文档数量庞大。在实际工作中,依赖人工检索或“Ctrl+F”反复搜索关键信息,不仅耗费大量时间,还容易遗漏或出错。随着业务复杂度提升,传统基于规则的方式愈发难以满足需求,企业亟需更智能的解决方案来实现文档内容提取。
痛点:人工检索与传统抽取的局限
传统文档内容提取往往依赖于规则设定,深度学习的训练模式往往需要大量高质量标注样本,且模型的适应性差。一旦文档的行文方式、版式或表达方式发生变化,原有规则便失效,模型准确率随之下降。
以医疗险理赔为例,各家医院的住院病案、出院小结格式完全不同,不同来源的文档存在大量非标准化版式,人工标注与维护成本极高,且难以保证泛化能力。金融、政务、法律领域的复杂文档同样存在类似问题,人工维护抽取规则不仅耗时耗力,还难以跟上业务变化。
解决方案:TextIn智能文档内容提取
TextIn基于自研语义模型与多模态文档解析引擎,推出智能文档内容提取能力,打破了传统方式的限制。其核心优势在于:
1. 零样本抽取,开箱即用
用户无需繁琐的样本标注,只需在TextIn智能文档抽取配置所需字段,例如在专利证书中设定“发明名称”“证书号”“申请日”,系统即可自动识别并提取对应信息。这种零样本抽取模式,大幅降低了实施成本,实现了真正的“即配即用”。
2. 优秀的泛化性
TextIn文档内容提取基于海量数据进行预训练,具备强大的语义理解能力。无论医院病案还是企业合同,即便版式和写法差异极大,模型依然能够准确抽取关键字段,避免传统模型在新场景下“失灵”的问题。
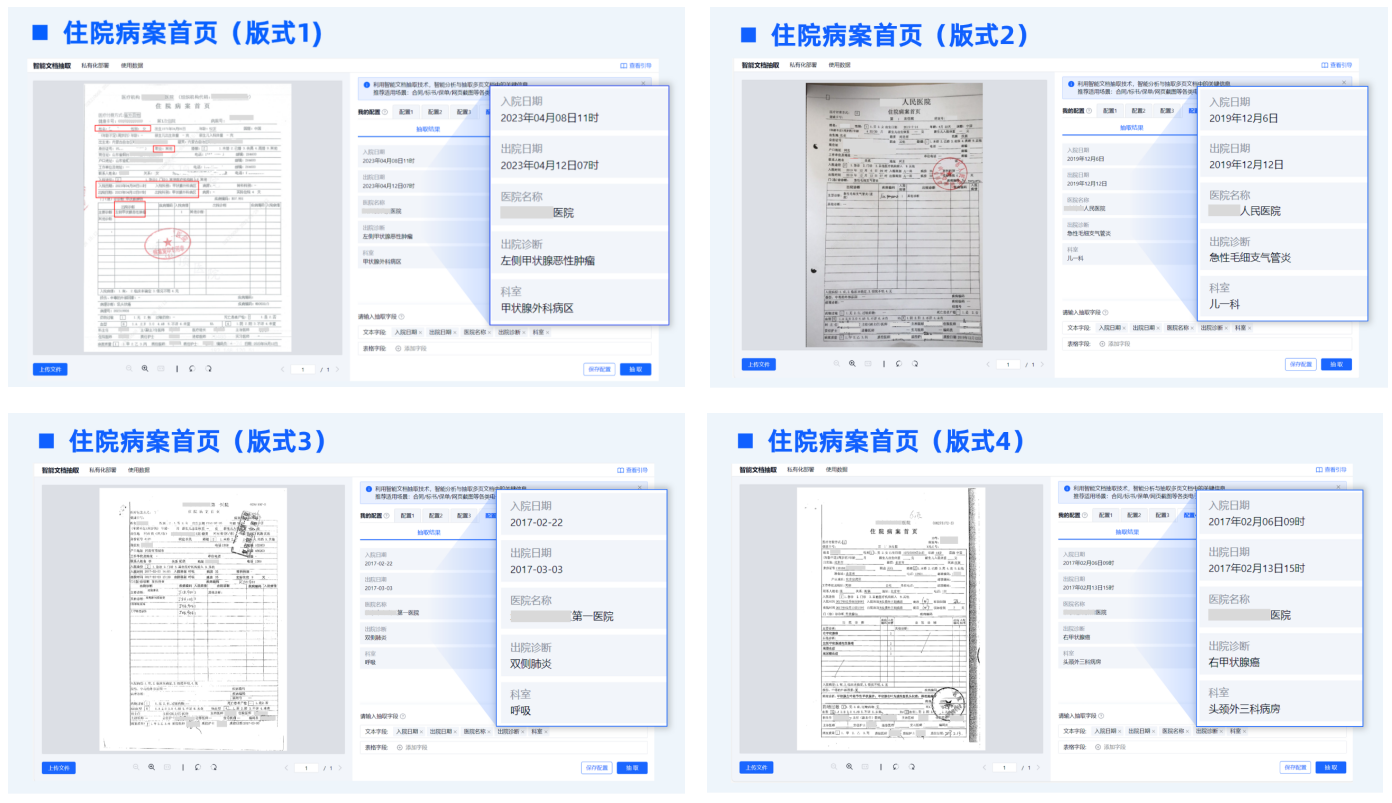
3. 复杂版面解析
在保险保单、财务报表等场景中,表格常常非标准、缺少边框,甚至以双栏方式展示。TextIn自研的版面分析引擎可以精准还原表格结构,提取出承保险种、保险金额、免赔额、保险费等关键信息,保障复杂版面下的抽取质量。
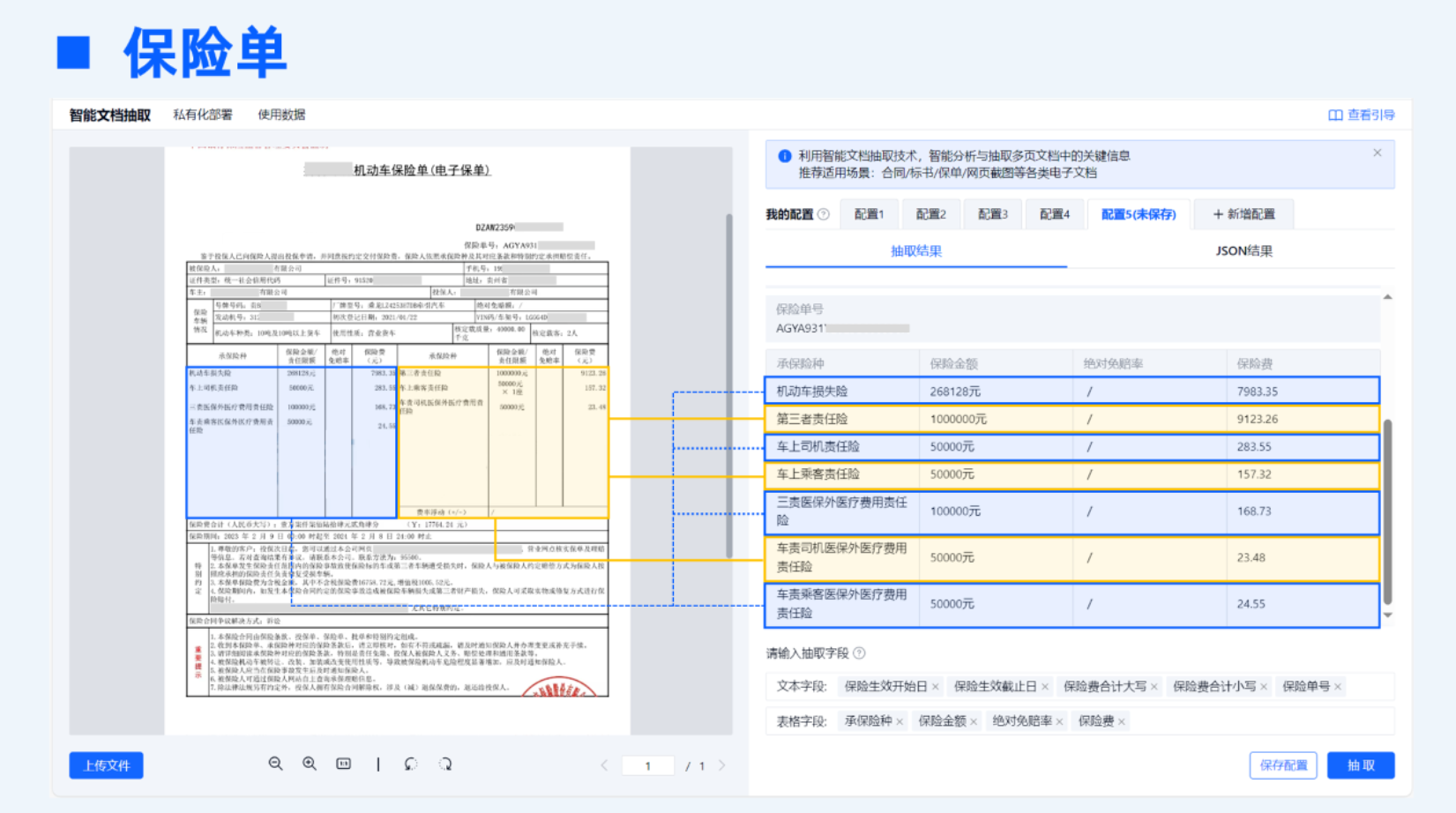
4. 多模态抽取能力
现实中的文档形式多样:双层PDF、扫描件、拍摄件,甚至带有手写签名、印章的票据。TextIn通过多模态识别与融合,能够在合同中识别手写签字,在财务单据中提取印章字段,实现跨介质的文档内容提取。

5. 长/短文本兼容
TextIn既适用于海外发票、国际信用证、不动产权证等单页短文档,也能处理长达百页的购销合同、基金合同和研究报告,保证无论文档长短,关键信息都能精准抽取。
应用价值:从“搜索”到“理解”
相比传统依靠规则匹配的方式,TextIn文档内容提取更像是理解而非搜索。它不仅能处理显性字段,还能基于上下文推理出隐含信息。
依托金融、政务、法律等多领域高质量语料的训练,TextIn语义模型既具备通识能力,也能精准处理行业专属概念。例如在处理研报信息中,可以自动识别出6*****是股票代码,对于“2022-2024”这一时间表达,系统不仅能识别多种写法,还能结合上下文准确推理出2023年的PE值。
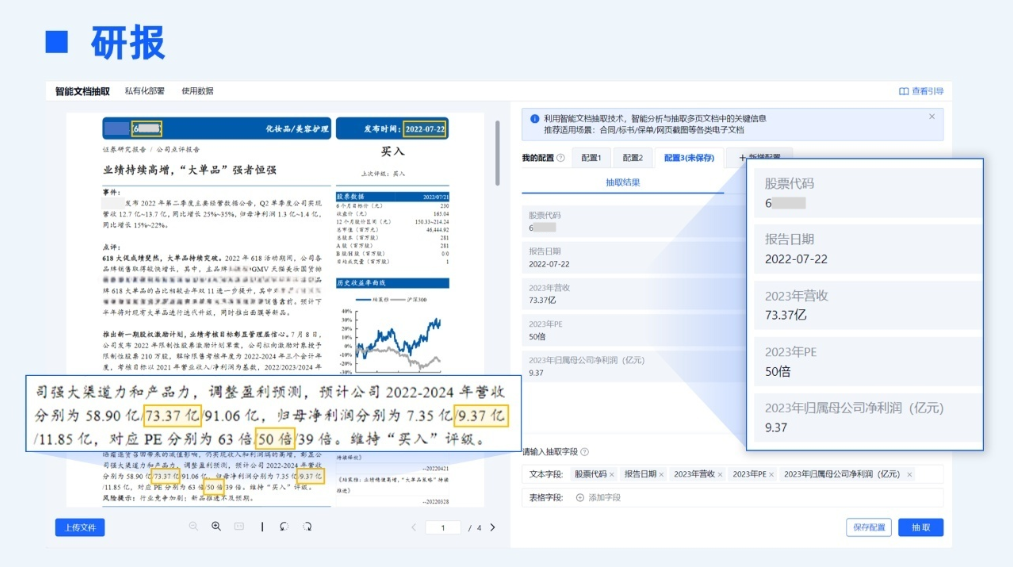
对于企业而言,这意味着文档不再是沉睡的数据堆,而能快速转化为可用的结构化信息资产。





