

PDF表格转Excel时,为什么容易出现错列、断行和表头丢失?
PDF 表格转 Excel 后出现错列、断行和表头丢失,通常不是因为“文字完全没有识别出来”,而是因为表格结构没有被完整还原。Excel 需要清晰的行列关系、表头层级、合并单元格范围和跨页连续性;但很多 PDF 更偏向版面展示,并不天然提供可编辑表格所需的结构关系。因此,导出的 Excel 可能看起来有文字,却仍然不适合继续复核、统计、入库或系统使用。
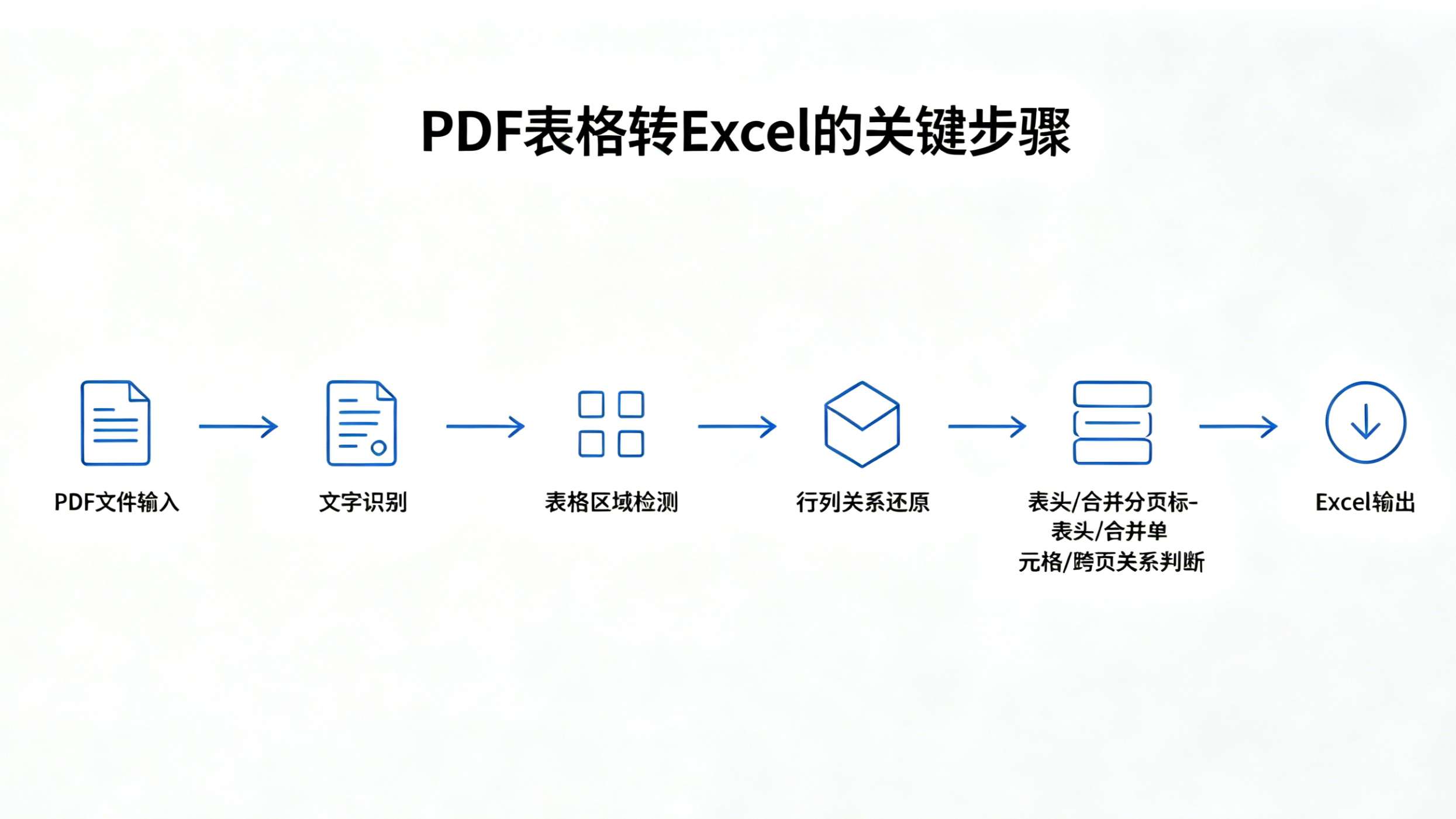
一、PDF 转 Excel 出错,问题通常不在“字”,而在“结构”
很多人遇到 PDF 表格转 Excel 出错时,会先怀疑 OCR 识别不准。但在复杂表格中,文字识别只是第一步。
真正影响 Excel 结果可用性的,是这些文字是否回到了正确的表格关系里:某个数值属于哪一列,某个字段受哪个上级表头约束,某个合并单元格覆盖了哪些行,第二页的表格是否延续第一页,表格标题、单位、注释是否仍然和主体数据保持关联。
这也是为什么有些 PDF 转 Excel 结果看起来“文字都在”,但业务人员仍然不能直接使用。因为 Excel 承接的不是一堆页面文字,而是一张可以编辑、筛选、复核和继续处理的二维表。
如果 PDF 中包含多层表头、合并单元格、跨页表格、无线表或嵌套表格,问题往往不只是“能不能导出 Excel”,而是是否具备复杂表格解析和结构还原能力。
二、错列、断行、表头丢失分别意味着什么?
PDF 表格转 Excel 的错误可以先分成三类看:错列、断行、表头丢失。它们看起来都是格式问题,但背后对应的是不同的结构判断失败。
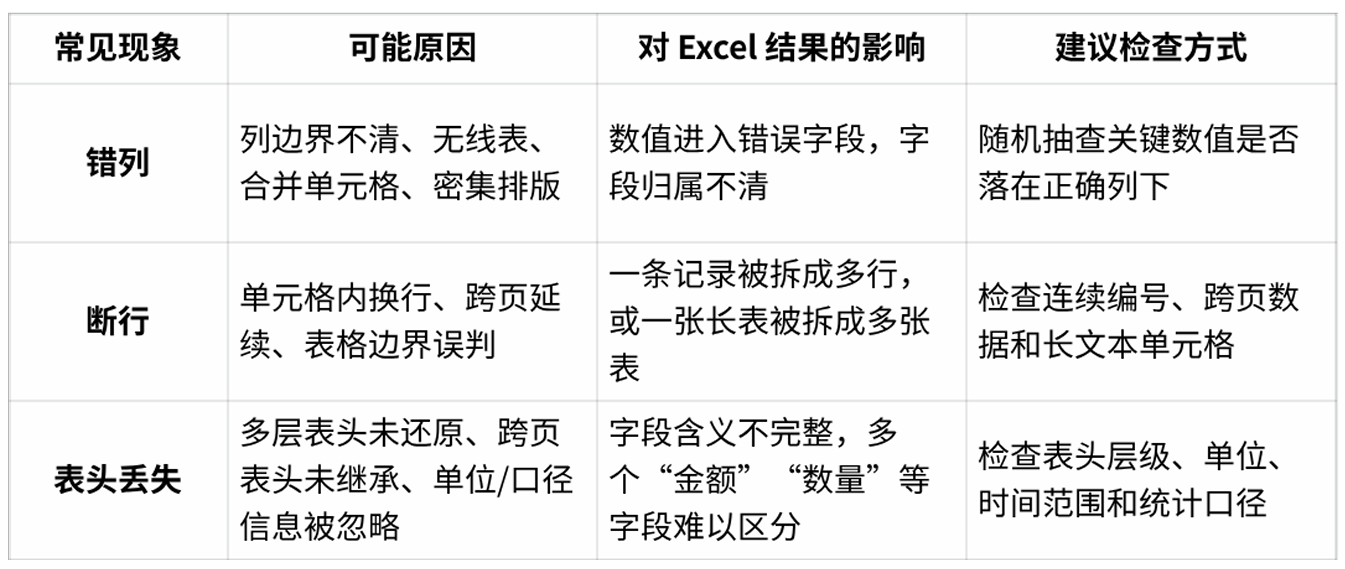
这张表可以作为初步判断。它不能替代正式评测,但能帮助你快速定位:问题到底来自文字识别,还是来自表格结构还原。
三、为什么会错列?因为字段归属没有被正确判断
错列是 PDF 表格转 Excel 中很常见的问题。它表面上是列的位置错了,本质上是字段归属错了。
比如,一个金额本应属于“本期收入”,却被放到了“上期收入”下面;一个检测结果本应对应某个检测项目,却被错放到相邻项目行里;一份报价清单里的数量、单价、总价都识别出来了,但列与列之间发生偏移,后续计算就可能失去参考价值。
错列通常和三类结构有关。
第一是列边界不清晰。无线表、弱边框表格、密集小字表格中,系统需要根据文字位置、间距和上下文判断列边界。如果边界判断不准,相邻列就可能被混在一起。
第二是合并单元格。合并单元格常用来表示上级分类或共享字段。人阅读时,会自然理解“下面几行都属于这个分类”;但如果解析结果只保留文字,没有保留覆盖范围和继承关系,导出到 Excel 后就可能出现分类缺失或字段错配。
第三是复杂版式干扰。页眉、页脚、注释、印章、图文混排、表格旁边的说明文字,都可能增加表格区域检测和行列切分的难度。
所以,判断 PDF 表格转 Excel 是否可用,不能只看“文字有没有出来”,还要看表格结构还原是否准确。
四、为什么会断行?因为跨页、换行和表格边界容易被误判
断行通常有两类表现。
一种是同一行数据被拆成多行。比如单元格里的文本本来只是自然换行,但导出到 Excel 后被识别成了新的行,导致一条记录变成两条记录。
另一种是跨页表格被拆断。很多企业 PDF 表格不会刚好在一页内结束,尤其是财报附表、招投标清单、检测报告、物流明细、质检记录等长表格,经常会跨页。第二页可能没有完整表头,也可能只延续上一页的部分字段。如果系统没有判断前后页是否属于同一张表,导出结果就容易变成多张断开的表。
跨页表格难点不只是“把两页拼起来”,还包括表头是否继承、列数是否一致、页码和注释是否干扰、上一页末尾和下一页开头是否存在连续关系。处理不好时,Excel 中就可能出现断行、断表、重复表头或字段缺失。
五、为什么会表头丢失?因为多层表头不是普通标题
表头丢失看起来只是少了几行标题,但在复杂业务表格里,它经常意味着字段含义丢失。
很多 PDF 表格并不是单层表头,而是多层表头。比如上层表头是“收入”和“成本”,下层表头是 Q1、Q2、Q3、Q4;或者上层是“本期”“上期”,下层是“金额”“占比”“同比”。如果只保留最底层字段,Excel 中可能会出现多个重复的“金额”“占比”,但无法判断它们分别属于哪个业务口径。
表头里还可能包含单位、币种、统计口径、时间范围、数据来源或备注说明。这些信息如果在 PDF 转 Excel 时被丢掉,后续人工复核、数据入库、知识库检索或业务系统调用时,都可能需要重新回到原文确认。
因此,表头识别不只是识别几行文字,而是要尽量保留表头层级、字段路径和上下文关系。对于多层表头较多的 PDF,建议重点检查导出的 Excel 是否仍能看出“字段从属关系”,而不是只看表格是否被成功导出。
六、普通 PDF 转 Excel 和复杂表格解析有什么区别?
普通 PDF 转 Excel 更偏向格式转换,重点是把 PDF 中的表格内容转成可编辑表格。对于简单、规则、边框清晰的表格,这类方式通常已经能满足基础整理需求。
复杂表格解析更关注结构、语义和下游可用性。它不仅要把表格导出来,还要尽量保留行列关系、表头层级、合并单元格、跨页连续性、上下文信息和原文位置,方便后续入库、检索、复核、知识库、RAG 或自动化流程使用。
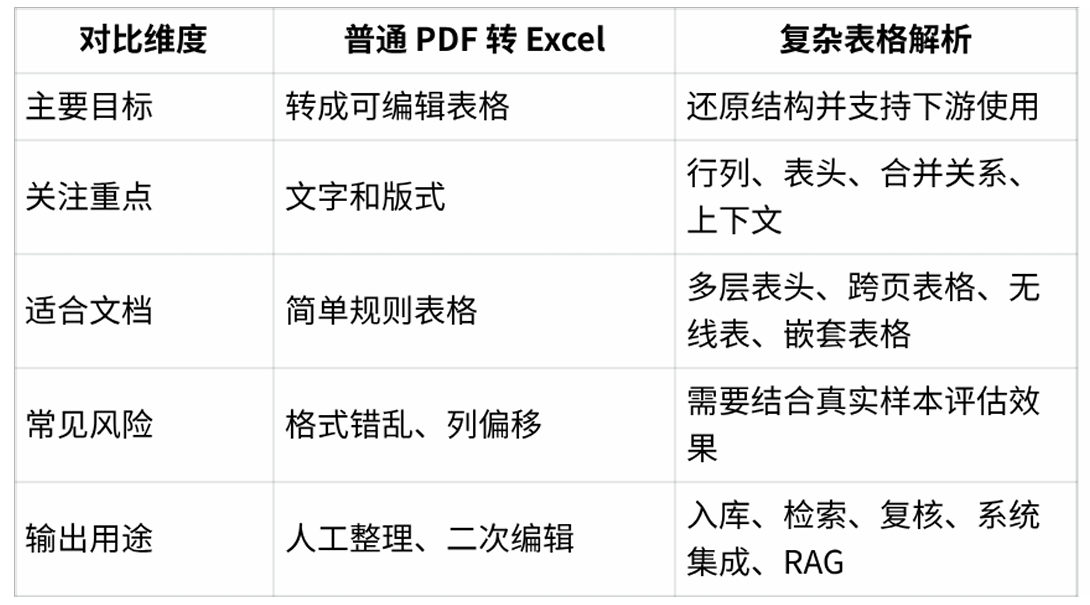
这并不是说普通 PDF 转 Excel 没有价值,而是说:当业务目标从“把表格转出来”变成“让数据继续被系统使用”时,评估重点就需要从文件格式转向表格结构。
七、导出 Excel 后,建议检查这 6 件事
如果你已经把 PDF 表格转成 Excel,可以先用下面 6 个问题判断结果是否适合继续使用。
行列是否对齐:每个数值是否放在正确字段下? 表头是否完整:多层表头是否保留了上下级关系? 合并单元格是否可理解:分类、分组和共享字段是否仍然清楚? 跨页表格是否连续:同一张长表是否被错误拆成多张表? 上下文是否保留:标题、单位、币种、备注、脚注是否仍能关联到表格? 输出是否便于下游使用:Excel 是否便于复核,JSON 是否便于系统入库,Markdown 是否便于知识库或 RAG 使用?
这份清单不能替代正式评测,但适合作为初步筛查。尤其是企业真实文档版式差异较大,不建议只用标准样例判断工具效果,更建议准备多种真实样本进行测试。
八、如果业务里有大量复杂 PDF 表格,应该怎么处理?
如果只是偶尔处理简单表格,普通 PDF 转 Excel 工具可能已经足够。但如果业务中长期存在财报、研报、检测报告、招投标文件、物流单据、医疗报告、制造业质检报告等复杂表格,就需要更关注解析结果能否进入后续流程。
比较稳妥的做法是:先准备一组真实样本,覆盖清晰 PDF、扫描件、多层表头、合并单元格、跨页表格、无线表和业务字段较复杂的文档;再观察导出的 Excel 是否能保留字段归属、表头层级和跨页连续性;如果还需要进入数据库、审核系统、知识库或 RAG,则进一步检查 JSON、Markdown 等结构化输出是否满足下游任务。
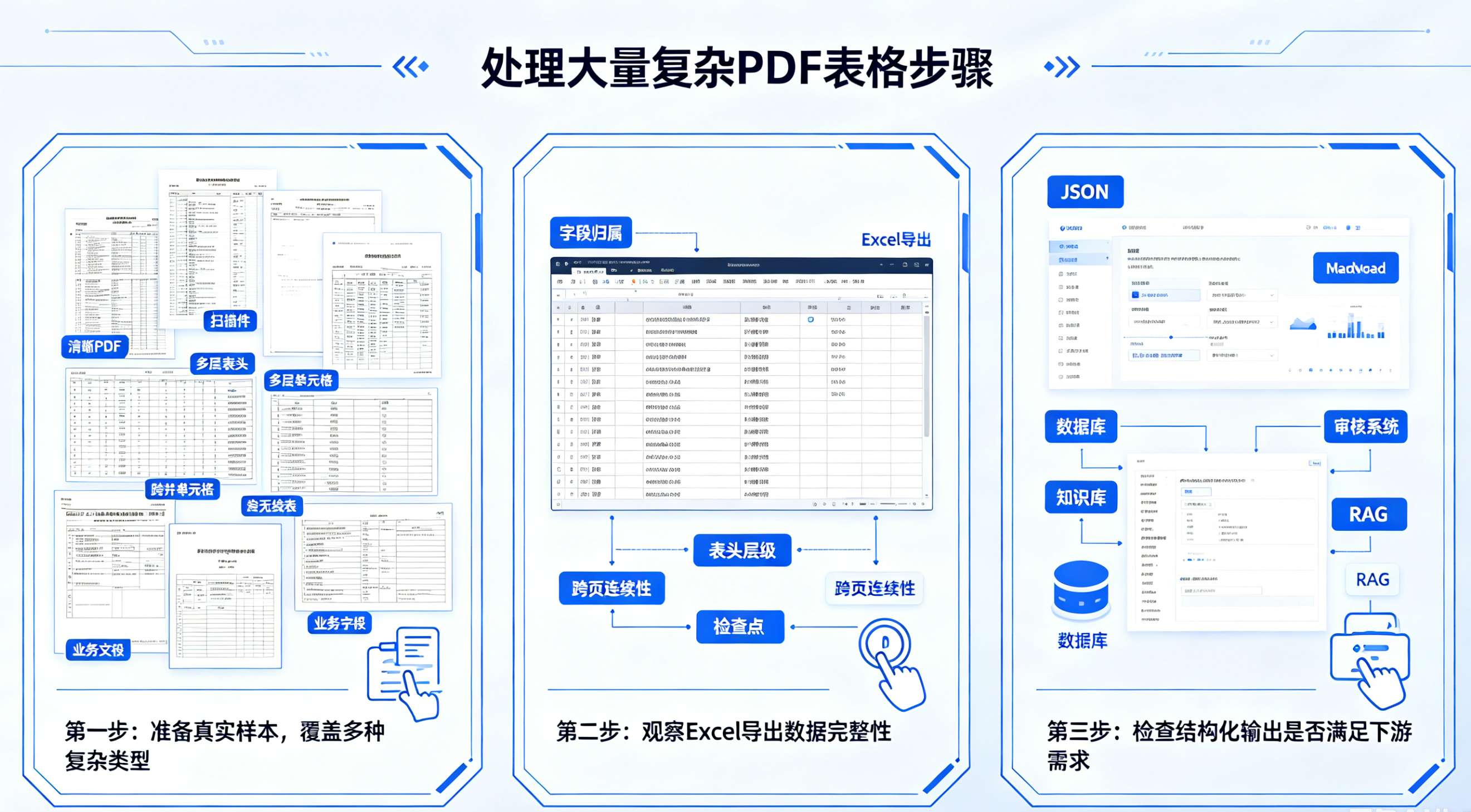
基于已有产品素材,TextIn xParse 面向复杂表格解析场景,支持跨页表格、多层表头、合并单元格、无线表、嵌套表格等复杂结构识别,并支持 Markdown、JSON、Excel 等结构化输出,可用于知识库、RAG、数据中台、审核系统、风控系统和自动化流程等场景。
如果你正在处理 PDF 表格转 Excel 中的错列、断行、表头丢失问题,可以注册并上传真实 PDF 样本,体验TextIn xParse 复杂表格解析能力,重点查看表头层级、行列关系、字段归属和跨页接续是否符合你的业务使用要求。
FAQ
1. PDF 表格转 Excel 为什么会错列?
常见原因是列边界、合并单元格、无线表或复杂版式没有被正确判断。文字被识别出来,不代表字段归属一定正确。建议检查每个数值是否回到了正确列和正确上级表头下。
2. PDF 转 Excel 后表头丢失怎么办?
可以先检查原始 PDF 是否存在多层表头、跨页表头或表头与正文分离的情况。如果表头包含单位、时间、分类或统计口径,建议使用更关注表头层级和上下文保留的表格解析方式进行测试。
3. 跨页 PDF 表格为什么容易断开?
跨页表格需要判断前后页是否属于同一张表,以及第二页是否继承第一页表头。如果只按单页处理,就容易出现断表、重复表头、字段缺失或多张表拆分的问题。
4. 扫描件 PDF 表格转 Excel 会更难吗?
通常会更难。扫描件可能受到清晰度、倾斜、噪声、边框不清、字体较小等因素影响。是否适合自动解析,仍需要结合具体样本测试。
5. 复杂表格解析和 PDF 转 Excel 是一回事吗?
不是完全一回事。PDF 转 Excel 更偏向格式转换,复杂表格解析更关注结构还原和下游使用,包括表头层级、合并单元格、跨页关系、上下文和多格式结构化输出。













