单月30k+ Downloads!一款头部Embedding开源模型
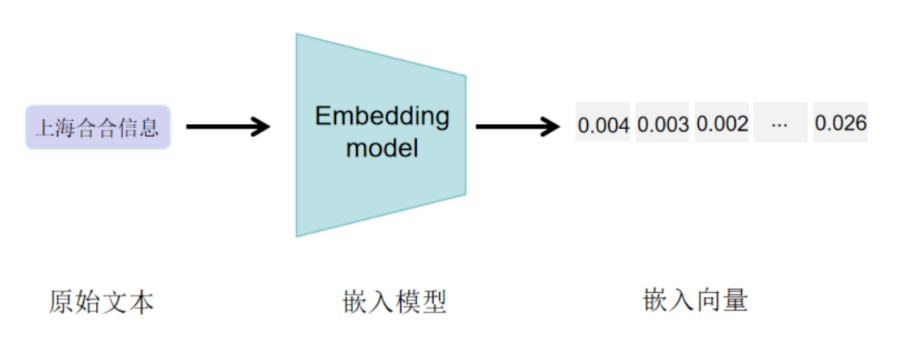
在数字化转型的浪潮中,文本数据的处理和分析成为了各行各业关注的焦点。如何将人类阅读的文本转换为机器可理解的形式,并且能够准确地召回和提取这些转换结果,成为了提升我们工作效率和体验的关键。
无论是从社交媒体中提取情感倾向,还是对大量文档进行内容相似性分析,或是在复杂的对话系统中实现精准的语义理解,文本向量化(Embedding)技术都扮演着至关重要的角色——纯文本无法通过数学方式计算,而转换为向量后,即可进行最基础的数学运算。
今天,我们和大家分享一款令人兴奋的开源模型——acge_text_embedding。今年三月,acge模型在Massive Text Embedding Benchmark (MTEB) 中文榜单(C-MTEB)登顶第一,目前模型已在Hugging Face和Github平台开源。
01项目简介
acge_text_embedding模型由TextIn团队开发,是一个通用的文本编码模型——可变长度的向量化模型。Embedding是一种用于机器学习和自然语言处理领域的表示技术,它将高维的离散数据(如单词、句子或者图像的特征等)转换为低维的连续向量,这些向量能够捕捉到数据的语义特征和关系,将单词、短语或整个文档的语义和上下文信息封装在一个密集的、低维的向量空间中。
acge模型使用了Matryoshka Representation Learning,建议使用的维度为1024或者1792。
在Hugging Face平台上,acge模型单月下载量为30,423。
02性能优势
优秀的召回效果:采用对比学习技术,通过最小化正对之间的距离和最大化负对之间的距离来呈现文本语义表示,提升整体召回效果。
强大的模型泛化能力:基于多场景、高质量、数量庞大的数据集,打造强大泛化能力,加快模型收敛。
改善模型“偏科”与遗忘问题:技术开发过程中,采用多任务混合训练,多loss适配场景,适应各种下游任务,避免模型“偏科”;引入持续学习训练方式,改善引入新数据后模型灾难性遗忘问题。
更快的处理速度:运用MRL技术,训练可变维度的嵌入,提高处理速度,降低了存储需求。
03使用方法
重现C-MTEB结果示例代码



在sentence-transformer库中的使用方法,并算出两个文本的相似度:

在sentence-transformer库中的使用方法,选取不同维度的向量:

04现有应用
当前,acge模型已在多个应用场景下展现其优势:
文档分类:
通过ocr技术精确识别图片、文档等场景中的文字,利用acge强大的文本编码能力,结合语义相似度匹配技术,构建通用分类模型;
长文档信息抽取:
通过文档解析引擎与层级切片技术,利用acge生成向量索引,检索抽取内容块,提升长文档信息抽取模型精度;
知识问答:
通过文档解析引擎与层级切片技术,利用acge生成向量索引,定位文件内容,实现精准问答。
更多模型细节,可以到项目地址查看👇:
链接:https://huggingface.co/aspire/acge_text_embedding
模型API调用:https://www.textin.com/market/detail/acge_text_embedding





