用户的声音| 出色的表格解析能力!TextIn文档解析助力金融信息化企业数据底座建设
最近,收到了一些重要的用户反馈——它们来自各个行业领域的先锋用户,“大模型+”的前沿探索者。
对AI从业者来说,今年诺贝尔奖的公布像一剂强心针,调动起了大家的热情,在世界范围内更广泛地看见AI的无限可能性。
TextIn团队和我们的用户都是其中的一员。我们探讨各自的赛道和前进的方向,并在不同的领域注入AI的力量。
我们将与大家分享与文档解析这款大模型加速器有关的故事——
1、AI+SAAS,资本市场信息化力量
介绍一下我们今天故事的主角:Z公司,专注于资本市场信息化业务,公司利用人工智能、云计算、大数据、模式分析等技术,为上市公司、拟上市公司、金融机构、监管机构等主体提供AI+SAAS服务产品,这也是我国资本市场合规科技与监管科技的代表产品。
Z公司的主要业务和产品覆盖而不限于以下领域:
- 企业平台:公司核心产品,从信息披露、合规交易、监管动态、股东分析、舆情监控、投资者关系、资本运作、三会管理等八大维度提供服务,实现了董办事务的“互联网+”预想。
- 特定客户股票管理系统:该系统为证券公司提供服务,帮助上市公司大股东、董监高股票交易合规化,通过科技手段建立合规交易管理的标准化服务体系。
- 企业法库:构建了合规领域重要的信息数据库,包括法规条文和业务分类,在此基础上构建的合规智库,得到了市场的充分认可。
在Z公司产品发展过程中,出现了一项重要关卡:如何获得高质量的数据基础与及时的数据更新能力。
2、技术难点:“唤醒”PDF中的数据与信息
不论是平台数据还是智库信息,Z公司大部分业务都需要海量且及时更新维护的数据,而这些数据大多来自公告、研报、ESG报告等文件,它们的格式则以PDF为主——同时包含电子档与扫描档。
要将PDF文件转化为机器可读的Markdown或Json格式,文档解析能力必不可少,Z公司需要解析的文件类型包括:
- 公告:上市公司或银行等发布的实时公告。
- 半年报、年报:来自上市公司,一般会在一定时期内集中发布及入库。
- 分析报告:业务需对文档内容做批注,需要以Markdown的形式在页面展示。
- 董监高信息:业务需抽取不同公司的董监高信息,一般而言,董监高信息包含在PDF文件某个章节的表格中。
Json或Markdown格式的基础数据源储存了文件中的详细信息,能够提供给下游应用完成信息抽取、在页面上展示方便客户查看或复制、或模型训练等等工作。
在Z公司的实际业务中,对PDF文件解析的重点落在文本(含阅读顺序)与表格的准确率上,部分业务需要从表格里抽取特定数据进行计算,而模型训练也主要基于文本和表格信息。
Z公司研发人员基于开源的pymupdf开发了结构化解析PDF模型,但在业务场景下,对以下几个问题不能很好解决:
- 完全或部分扫描档PDF,只能以图片的形式展示。
- 如果PDF使用了特殊的字体或编码格式,PDF原文看起来是正常的(人工浏览),但是解析出来的内容却是乱码。
- 对于线条极少或压根没有的表格(这类表格,我们称为无线表格)无法解析。
3、TextIn:翻越技术障碍
针对解析难点,Z公司研发团队尝试过很多开源的无线表格解析以及一些相关产品,最终选择了他们认为识别效果最佳的TextIn文档解析工具。
TextIn解析工具为上述问题提供了高质量的解决方案:
- 无线表格:实现准确的无线表格识别与解析,帮助业务部门更好地挖掘表格数据潜在的信息价值。
- 扫描PDF:基于TextIn在OCR与解析领域的长期深耕,在扫描件方面也能保持优秀的准确率。
- 乱码问题:应对使用特殊字体或编码的PDF文件,解决乱码干扰,获取正确信息。
在AI应用领域的数据基础中,不论对于大模型还是业务的程序化解析,图片是一种并不便捷的信息储存方式—它为数据处理与理解制造了障碍,而TextIn通用文档解析工具能把图片或扫描页里的文字和表格准确地识别出来,放大其中信息的价值。
此外,值得一提的是,TextIn此前发布的SDK支持用户根据需要单独提取表格或公式、手写内容等等自己需要的元素。在与年报、研报相似的文件类型中,表格往往包含重要数据,TextIn SDK的功能更新为用户提供了更便捷的使用方式。
4、难点+重点:无线表格
无线表格由于其结构的特殊性,一向是PDF解析中的重难点。而在金融类文件中,无线表格的出现频率相当高,甚至是财务报表的主要组成类型之一。
下面让我们来看一个案例:
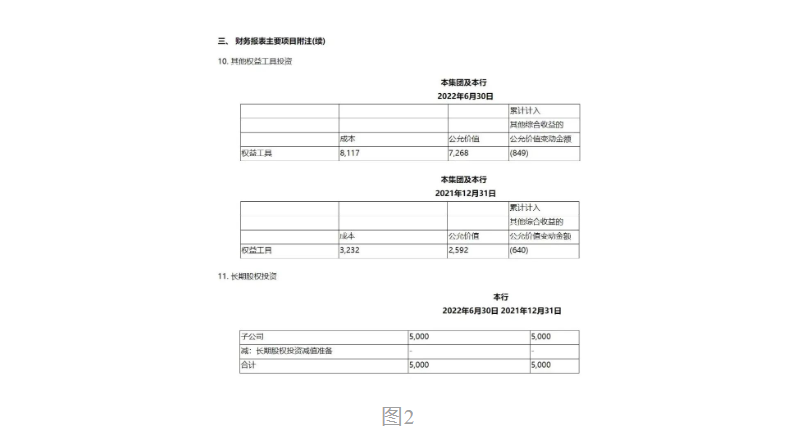
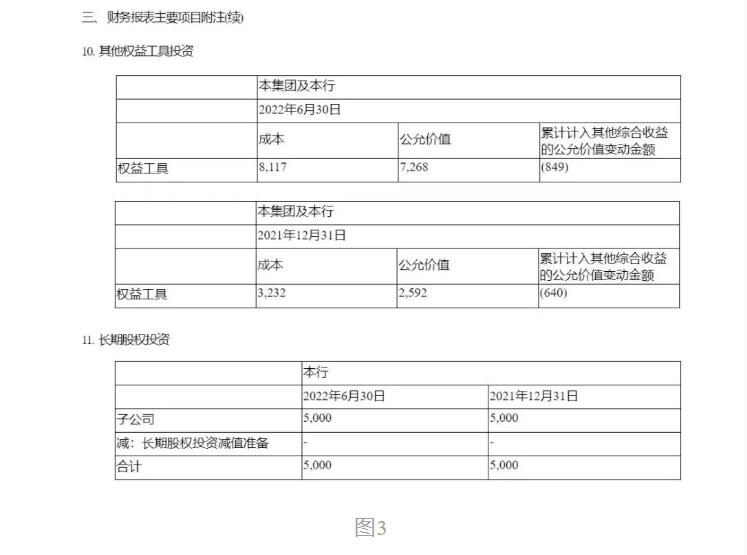
这是一份财务报表中的无线表格,图1是我们可以在PDF文件中看到的原文表格。

图2和图3分别显示了开源模型与TextIn文档解析的输出结果。可以看到,前者中无线表格的表头,尤其是单行,都未识别出来;后者表头识别正确、完整,同时做到了正确合理的单元格合并。
五、我们的下一步
在目前的技术基础上,TextIn团队将致力于继续加强解析能力:表格方面,我们的用户已经提出,希望能获取每个单元格内容的坐标信息,并在嵌套表格、跨页表格识别与关联方面取得进一步进展;对于字体格式,包括粗体、斜体、不同字号的识别,我们将努力提供更精细化的服务。
同时,从多种形式调用到优秀的前端界面分享,我们会不断优化用户的使用体验,让文档解析更加便捷。
👇更多福利、大模型应用技术学习材料,点击以下连接即刻领取!





