TextIn ParseX文档解析SDK工具新增Java版本

TextIn ParseX通用文档解析是一款大模型友好的解析工具,支持将pdf文档、jpg、img图像等文件快速转换为markdown格式,支持各类表格、公式解析,帮助大语言模型的数据清洗和文档问答任务。此前,为了让用户获得文档解析引擎返回的丰富版面元素,我们推出了一系列的sdk函数,包括目录树、公式、表格、图片、全文markdown等结果的获取函数;同时开源了前端可视化组件,满足用户个性化的校对使用需求。
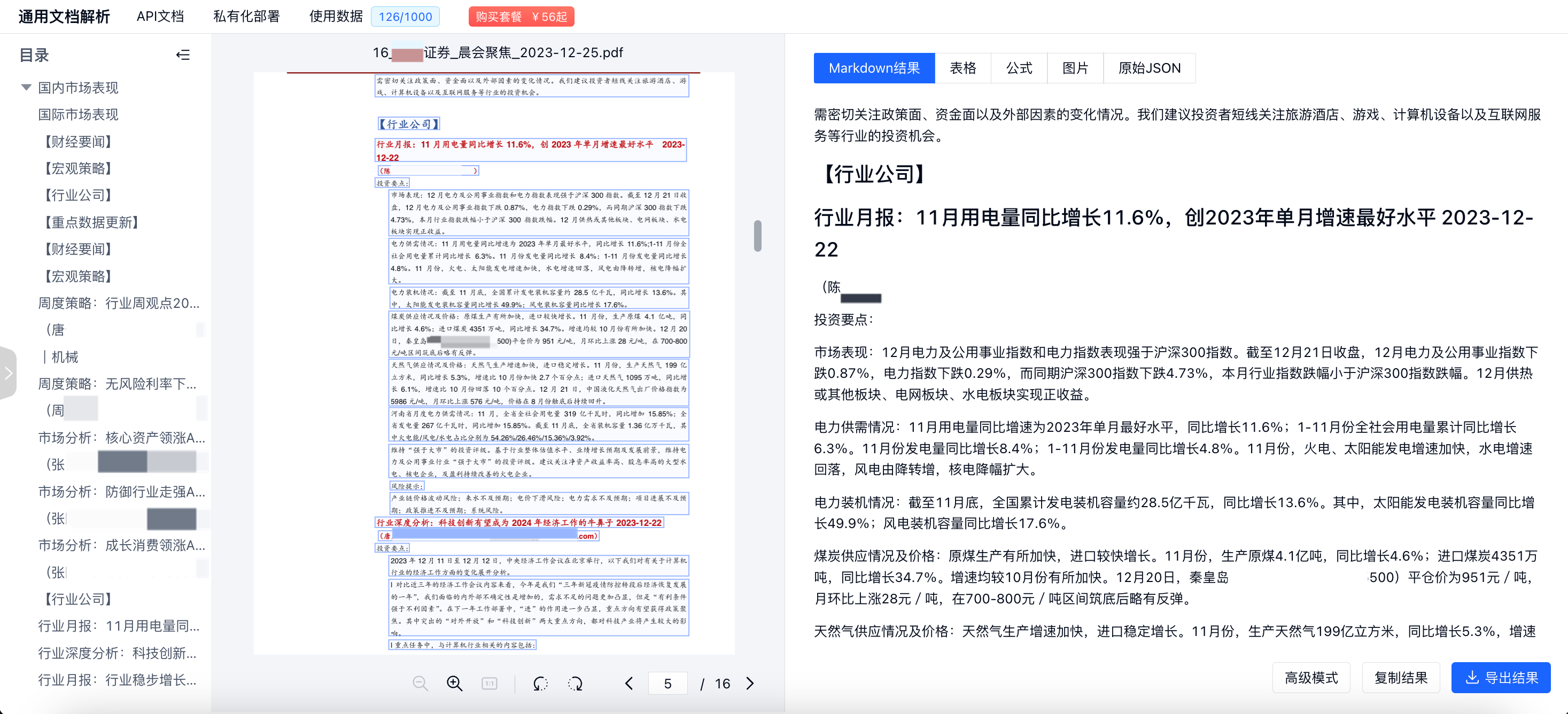
近日,为便于使用Java语言的开发者调用文档解析引擎,TextIn ParseX SDK工具新增Java版本。
SDK工具Java版地址:https://github.com/intsig-textin/parsex-sdk/tree/main/java

这是一套标准的多平台支持的Java SDK,帮助开发者解析pdf_to_markdownRestful API返回结果,获取对应的版面元素的数据结构。
开发者只需下载jar包,并导入到自己的项目中即可使用。

在项目中引入jar包后即可使用。


示例展示了如何使用TextInParseX SDK来解析PDF文件并提取其中的各种元素。完整示例代码请访问上方Github链接,查看TextInParseX/src/test/TestSDK.java。

首先,导入必要的包并初始化 ParseXClient:

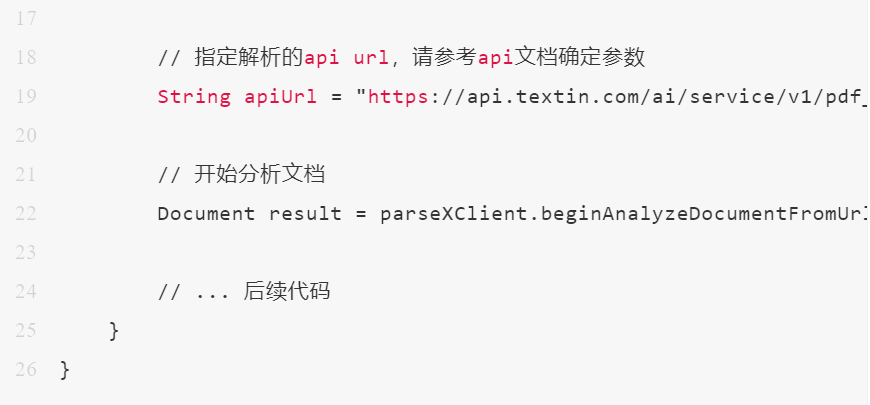

提取并打印文档的Markdown格式内容:


获取并打印文档中的所有文本内容:


获取并打印文档中的所有表格:


获取并打印文档中的所有段落和文本行:



获取并打印文档中的所有图片信息:


获取并打印文档中所有图片的OpenCV Mat对象:


以下示例展示了如何处理文档中的每一页,为表格、图像、段落和文本行添加边界框,并保存结果图像:



这个方法会为每个页面下载图像,然后在图像上绘制矩形来标注表格单元格(红色)、图像(黄色)、段落(绿色)和文本行(蓝色)。处理后的图像会以 "image_result_[页码].jpg" 的格式保存。


这个方法会将表格转换为excel文件,并保存到指定路径。如果有多个表格,会生成多个sheet。

使用此示例时,请确保:

这个示例展示了如何使用TextIn ParseX SDK的主要功能,包括提取Markdown内容、文本、表格、段落、图片信息等。您可以根据需要修改这个示例,以适应您的具体使用场景。
如果没有OpenCV环境或版本不匹配,操作方法详细请见Github主页。

后续我们将开放更多的sdk函数,也欢迎各位用户朋友给我们提更多的类似需求。
💡欢迎试用TextIn文档解析,学习更多大模型应用技术!





