TextIn文档解析表格处理模型优化,显著提升表格解析性能
近期,TextIn通用文档解析最新推出表格处理优化版本。
此前版本中,表格解析处理针对有线表格与无线表格预先分类,并基于框线进行模型预测。在运行过程中,我们发现,分类错误问题对表格解析准确率有负面影响。
本次优化主要改善了表格识别效果,以统一方案替代有线表格与无线表格分类处理方法,减少了级联损失,大幅度提升表格全对率。
通用文档解析链接:
https://www.textin.com/market/detail/pdf_to_markdown
表格全对率指标包含了对文本全对率和结构准确度的测量。文本全对率评估的是,解析出的表格中每个单元格的文本是否与原始表格完全一致,没有遗漏、错误或多余的字符。结构准确度测量模型对表格结构的预测是否正确,排除错行、漏行或合并单元格错误等问题。
根据TextIn测试指标,一个表格中,文本或结构解析有任何问题,即判为错误。表格全对率不仅考虑了单元格的内容,还考虑了表格的层次结构和布局,以确保信息的完整性与准确性。
对于此前表格处理模型,技术团队诊断:解决过于依赖逻辑位置预测与跨cell填充问题,能够进一步提升表格引擎性能。
TextIn技术团队在当前表格解析模型及后处理算法的基础上,结合模型预测的位置信息和逻辑信息,引入轴对齐处理思路,避免仅依赖逻辑信息预测的问题,减少单元格划分错误的情况;通过上下文信息与行列查询,解决跨行列cell填充问题;基于表格内容OCR匹配,实现物理位置修正。经测试,优化版本表格全对率有显著提升。
我们将通过几个案例,直观展示本次表格解析性能优化的表现。


如图所示,左侧图片是无线表格解析中常见的bad case:合并单元格结构识别不准确。由于合并单元格有顶部对齐、垂直居中多种形式,在实际文档中版面复杂多变,在没有框线的情况下,更增加了解析模型的识别难度。
右侧图中可以看到,TextIn文档解析本次表格性能优化后,能妥善处理这类难点情况,实现正确的表格还原,保障下游信息处理的准确性。
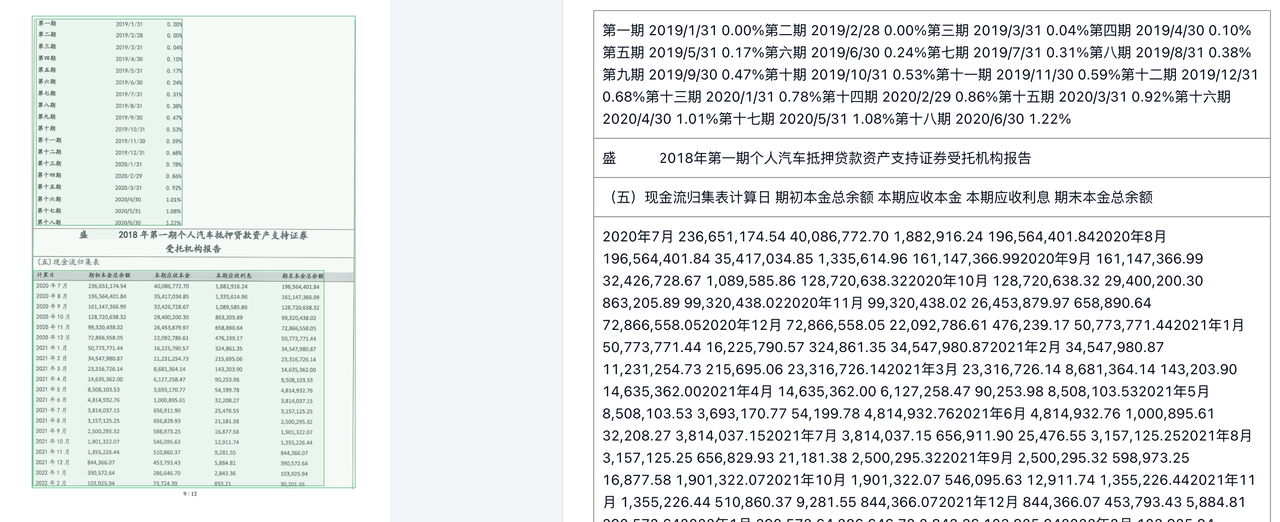
缺少结构信息的表格文字识别会丢失重要价值,导致数据成为无意义的数字。
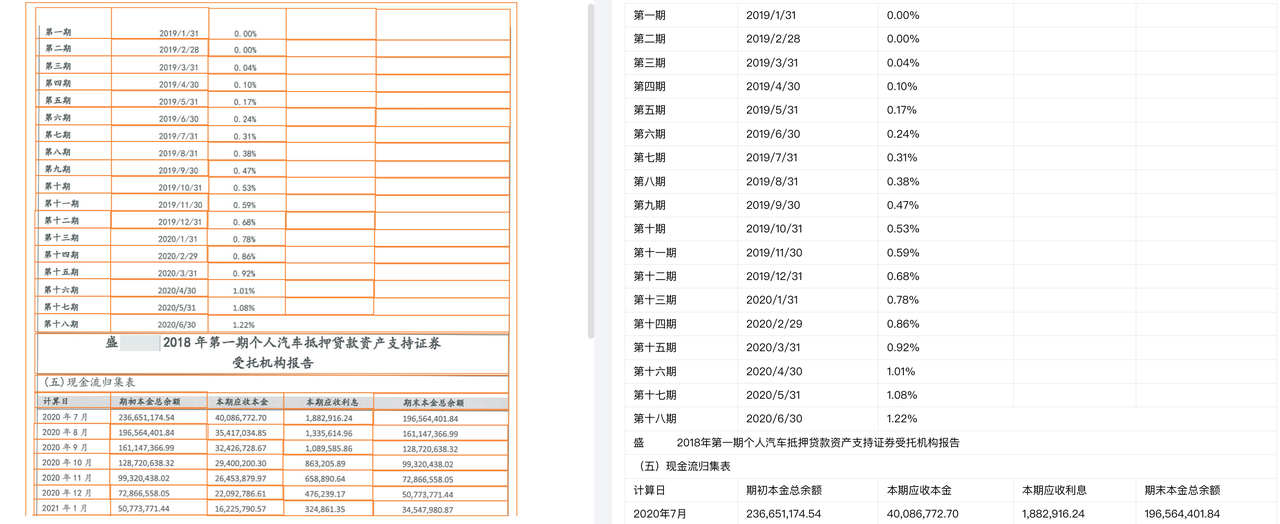
PDF文件中,拥有不同行列数的不规则无线表格在同一版面呈现的情况相当常见。以图中的金融机构报告为例,值得注意的是,TextIn本次表格优化后,模型会同步预测空cell,以提升整体表格解析准确率。


如图所示,对于清晰度较低、噪点多的扫描图像,优化后的表格模型也能实现精准的识别。
从具体案例来看,这一次表格解析优化,对解决单元格中的多行问题有优异的效果,用户如有产品说明书、体检报告、技术规格书等文件及其他类型多行复杂表格的解析需求,解析引擎的准确性和使用体验都将大幅度提升,能够满足教育、金融、数据处理等多种场景的精细化使用需求。

新版前端组件支持在线表格编辑,包括文字编辑、插入或删除行列、单元格合并与拆分等一系列常用表格编辑操作,便于直接通过窗口操作对识别结果进行修改或校正。
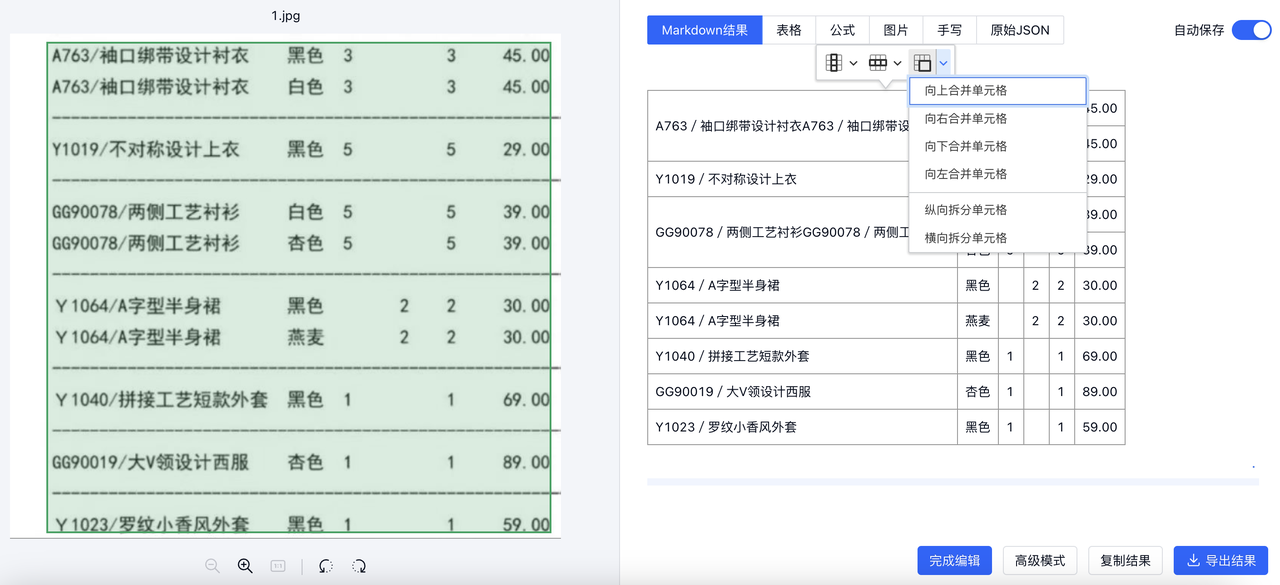
支持单独提取文档中的表格元素,导出为Excel。
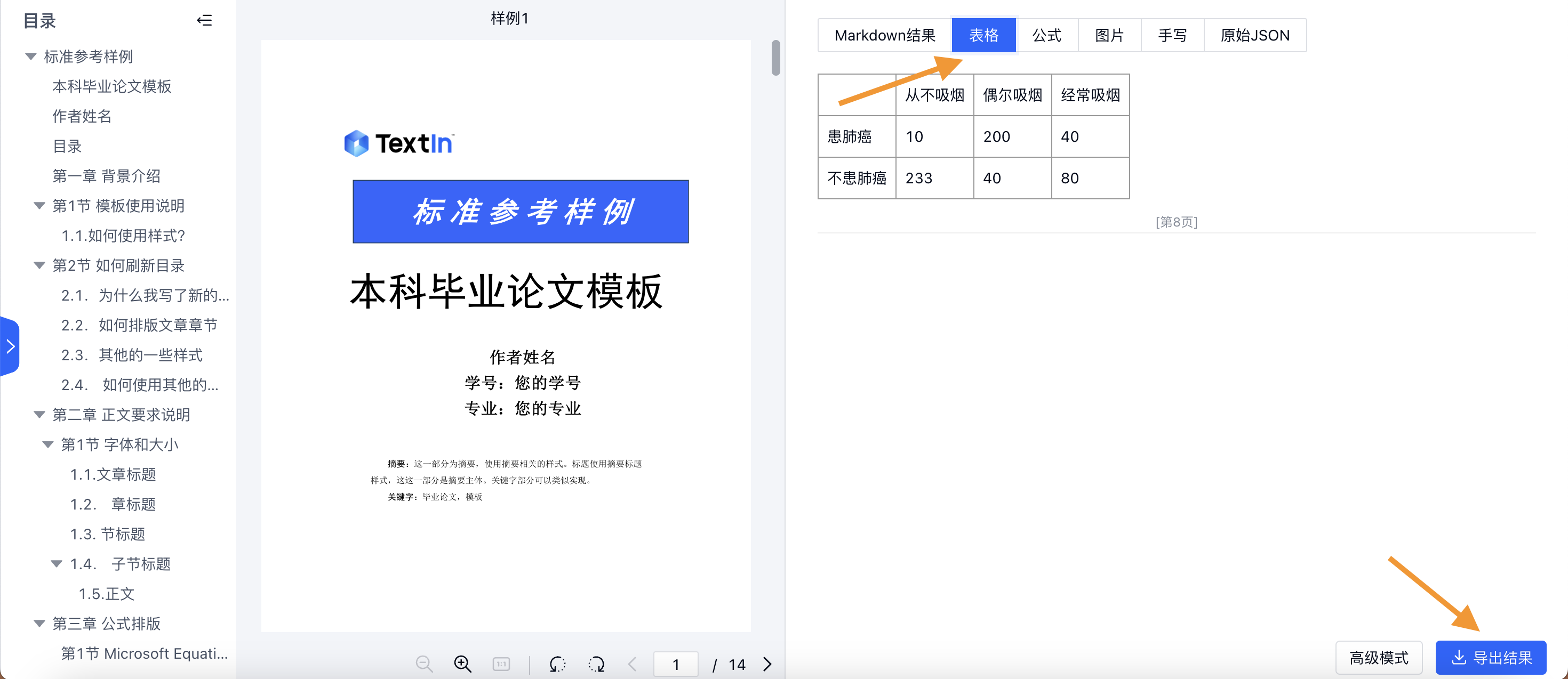

目前,SDK工具有Python和Java两种语言版本,支持获取并打印文档中的所有表格,也支持将表格转换为excel文件,并保存到指定路径。
具体代码请见:
https://github.com/intsig-textin/parsex-sdk
TextIn技术团队将继续完成检测网络优化,提升表格解析准确率。欢迎大家在线试用!





