

DeepSeek+文档智能处理:解锁企业“数据暗物质”的万亿价值
在当今数字化浪潮中,数据无疑是企业最宝贵的资产之一。企业中超过80%的数据以非结构化形式存在,如文档、邮件、报告、社交媒体内容等,合同文档、技术图纸、扫描文件等"沉默资产"的价值挖掘,已成为企业数字化转型的决胜战场。这些非结构化数据蕴含着巨大的价值,但由于其格式多样、结构复杂,难以直接被企业有效利用。
而随着大语言模型技术的迅猛发展,如DeepSeek等具有强大自然语言处理能力的模型不断涌现,为非结构化数据治理带来了新的曙光。在数字化转型的深水区,企业数据资产中的"暗物质"正在持续释放价值引力。
文档解析与抽取:开启宝藏的钥匙
文档智能处理的三大挑战
某大型金融机构的AI质检系统误将"不可抗力条款"识别为"免责声明";制造企业的图纸版本管理引发千万级质量事故……这些真实案例印证着文档智能处理的三大难题:
1. 格式黑洞:PDF/扫描件/图片等20+格式,每种格式都有其独特的结构和特点,且文本的排版方式复杂,可能存在多栏、嵌套等情况,这给内容提取带来了极大困难。
2. 语义迷雾:传统nlp模型对于语义理解较为生硬,合同条款、技术参数等专业领域的认知理解。
3. 关系迷宫:跨文档版本追踪、条款关联等拓扑结构重建。例如企业运营场景下,市场部门的调研报告、客户反馈邮件;研发部门的技术文档、实验记录;销售部门与客户沟通的聊天记录等。这些数据看似杂乱无章,却包含着客户需求、市场趋势、产品改进方向等关键信息。
传统OCR+正则表达式的组合拳,在复杂场景下的准确率极低,如同试图用算盘破解量子密码。
非结构化数据治理场景下的具体使用方法
“量子级”文档解析
在处理PDF文档时,许多企业过去依赖开源的传统OCR(光学字符识别)和PDF解析模型来提取文本信息。这类工具中比较流行的包括Apache PDFBox、PDFMiner以及Google支持的Tesseract OCR等。然而,尽管这些工具免费且易于获取,但在实际应用中却暴露出了一系列局限性。
首先,开源模型的效果往往不尽如人意,尤其是在面对复杂版面的文档时。例如,当遇到多栏布局、嵌套表格或非标准字体的PDF文件时,开源模型可能无法准确地将文本与图像区分开来,导致信息丢失或错误解析。另外,企业内部的非结构化文档数量巨大,对解析工具的性能及稳定性要求极高。综合来看,市面上的开源解析工具很难满足非结构化数据治理需求。
TextIn文档解析工具已经通过大量真实业务案例展现出了优越性:
解析速度快、稳定性强
100页长文档,TextIn文档解析在2秒内即可完成解析,单日数百万级调用量,成功率可达99.999%。以金融行业为例,数据时效性要求高、上市公司年报常常多达数百页,解析效率的提升至关重要。
准确性高:还原复杂版面元素
TextIn具备先进的版面分析技术,能够准确还原复杂扫描文件,无论是多栏文本还是带有图表的内容,TextIn都能实现清晰稳定的输出。其表格解析能力尤为出色,不仅支持有线表,还能精准识别无线表、跨页表格、合并单元格、密集表格、手写字符及公式等难点,保障表格信息无损转换,防止转换过程中出现数据丢失或变形的问题。

此外,TextIn对各种字体样式和PDF编码格式都有很好的兼容性,保证了不同来源的文档都能得到一致且高质量的解析结果。
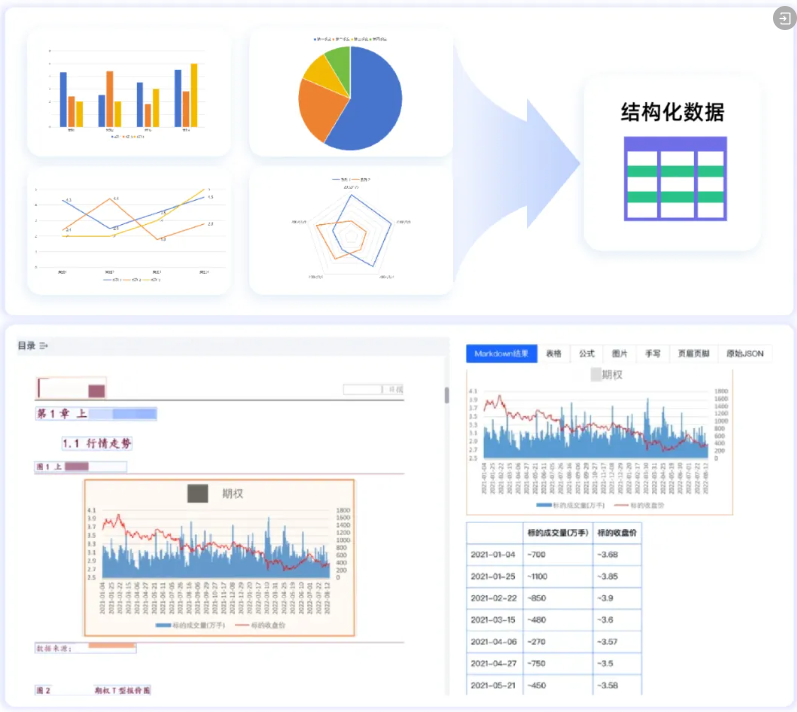
独家功能:图表解析,助力大模型读懂统计图表
TextIn文档解析近日上线新功能——图表解析,可以智能解析图表属性Chart,并以Excel格式精准输出,帮助大模型深度理解图表的结构、趋势和数据逻辑,让数据分析更高效。当前功能已支持饼图、折线图、柱状图、雷达图、散点图等多种图表类型。
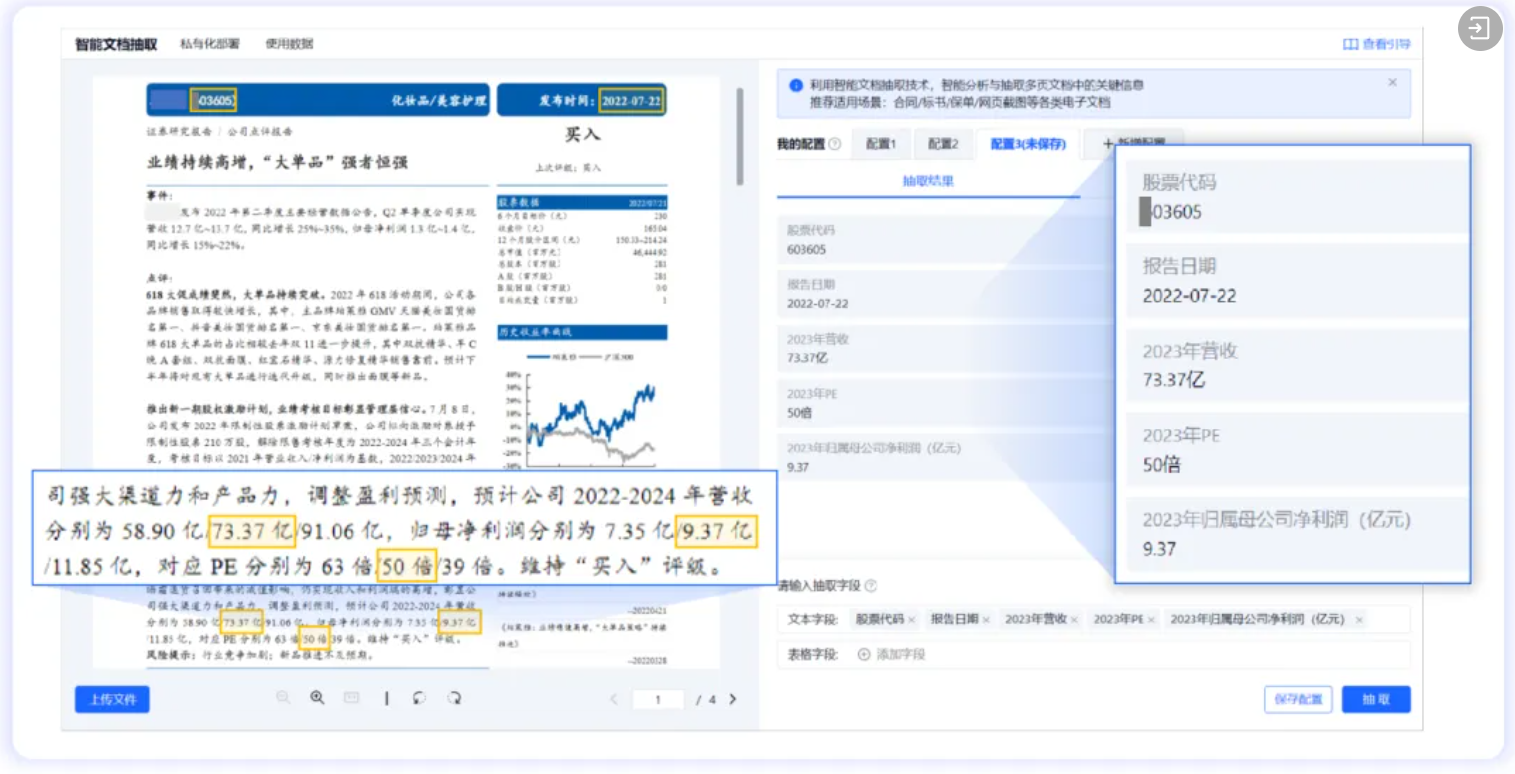
结合大语言模型的复杂结构处理
以 DeepSeek 为代表的大语言模型,凭借其强大的语言理解和生成能力,为文档结构化处理带来了创新的解决方案。大语言模型能够对各种类型的文档进行深入理解,不仅能够识别文本中的关键词、实体,还能理解文本的语义和逻辑关系,无需标注训练即可实现开箱即用的结构化抽取。其工作原理是通过对大量文本数据的预训练,学习到语言的通用模式和语义表达,并基于海量精标语料的监督微调(SFT),让模型专注于处理文档结构化任务,提升文本关键信息提取的准确度,并支持1Key多Value抽取、抽取结果字符级溯源定位,最大程度消除大模型幻觉带来的风险。
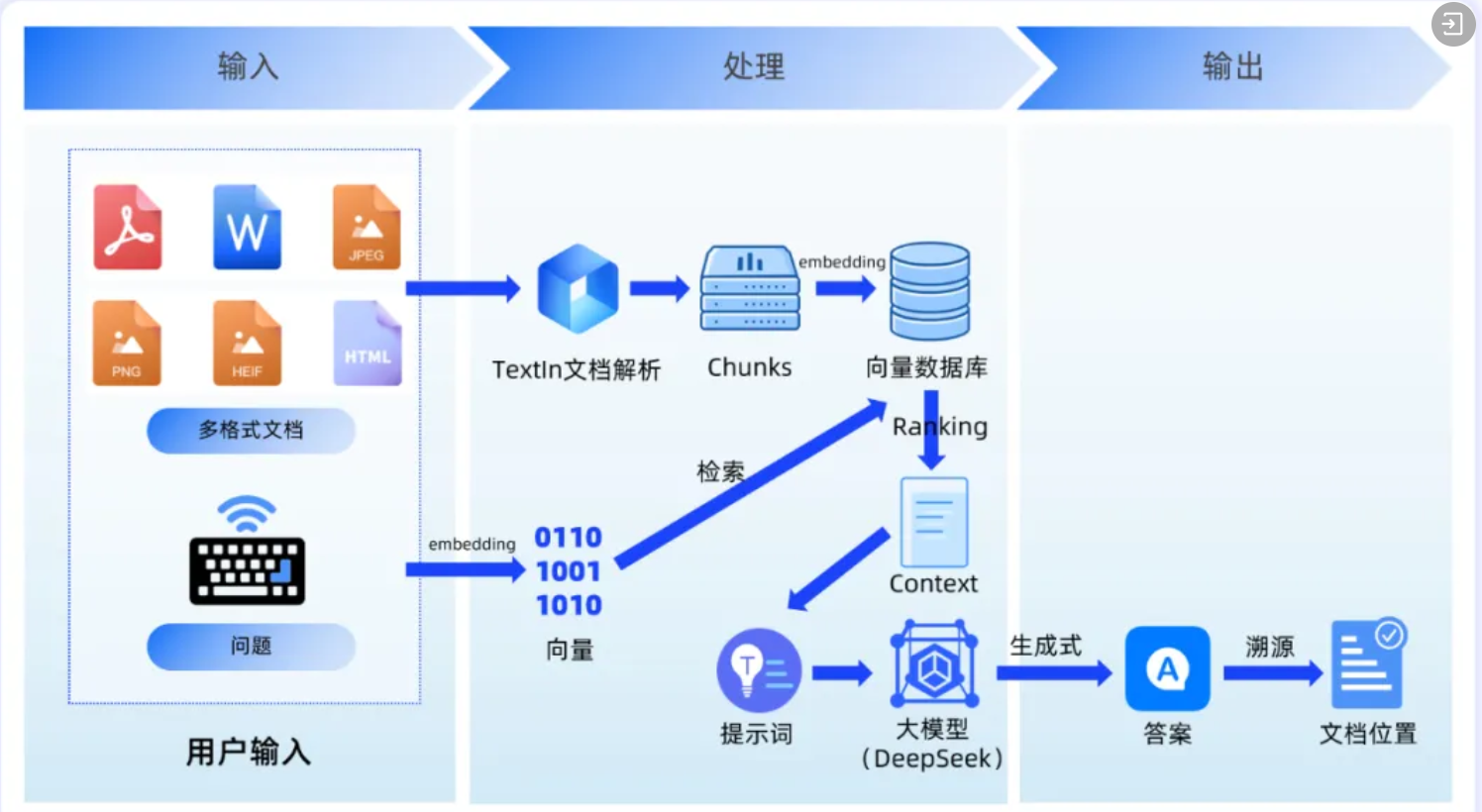
多技术融合的一站式解决方案
为了实现高效的非结构化数据治理,往往需要将多种技术进行融合。
数据整合与接入

文档解析及预处理
非结构化数据格式多样化、内容复杂性高、数据质量不一,预处理的目的是通过标准化的方式统一格式并清除噪声,为后续不同模态数据的检索、建模、训练和推理打下基础。
数据清洗:清除冗余数据、修复缺失值、图像去噪、图像质量增强。

文本内容解析:从大量的非结构化和半结构化的文本中,抽取有意义的实体、属性、关系等信息,形成结构化的知识。
质量监控:完整性、唯一性、有效性、一致性、准确性、及时性、关联性等方面的监控。
向量化存储及知识库检索
基于TextIn文档解析能力,将混杂的各类非结构化文档统一输出为大模型能“读懂”的文档格式,并进行向量化存储,自动构建元数据映射,依据向量相似度进行检索并反向映射获取源文件片段,赋能下游大模型任务,提升大模型回答正确率,并可实现原文溯源定位,便于信息复核。
价值落地的四大场景
准确、高效的文档解析和抽取能够为企业提供高质量的数据基础,从而支持后续的数据分析、挖掘和决策制定。
场景一:金融合规审核
在金融行业,银行需要对大量的贷款申请文档进行审核,这些文档包含了客户的个人信息、财务状况、贷款用途等内容。通过文档解析和抽取技术,能够快速、准确地提取关键信息,并进行风险评估,大大提高了贷款审批的效率和准确性。
场景二:医疗档案库
在医疗行业,医院的病历档案包含了患者的症状描述、检查结果、诊断报告等非结构化数据,通过对这些数据的解析和抽取,可以建立患者的电子健康档案,为医生的诊断和治疗提供全面的参考依据,同时也有助于医疗数据的统计分析和医学研究。
场景三:供应链流程优化
在生产制造领域,通过构建一套多技术融合的非结构化数据治理平台,实现了对生产报告、质量检测文档、供应商资料等各类非结构化数据的统一管理和分析,为企业的生产决策、质量控制和供应链管理提供了有力支持。
场景四:合同库建设
合同是公司法务管理场景下最终要的非结构化数据资产。作为合同管理系统的核心组成部分,文本库在合同的结构化和知识化方面发挥着关键作用:结构化的文本数据使我们能够精准地解析合同条款,提取关键信息,便于合同的查询和归档;合同文本库为合同的知识化提供了基础,通过建立条款库,企业可以制定和使用标准化的合同模板和条款,确保合同的一致性和合法性,促进合同标准化和规范化。在结构化、知识化的基础上,运用智能分析工具,从大量合同数据中挖掘有价值的信息,支持决策和风险管理。













