一份开发者自查清单:表格解析结果到手了,怎么判断能不能用?
你接入了某个文档解析API或者开源工具,跑完一批PDF,拿到了Markdown或JSON输出。下一步通常是什么?
对开发工程师而言,在没有 ground truth、也没有专用评测工具的情况下,评估解析结果只能先靠人工:初步查看输出文本,看起来是表格结构,文字没有缺漏,就暂且认为解析完成。
但这种“肉眼扫视”对复杂表格远远不够。复杂表格的解析错误往往不是缺了一整块,而是某个数字挂错了表头、某列被多拆了一栏、跨页的续表和上一页断开了。这些错误藏在看似完整的输出里,一眼扫过去很难发现,但一旦进入下游系统,就会引发连锁问题。
人工逐格比对当然可以发现问题,但耗时太长。尤其是要对比多个解析方案时,工作量会成倍增加。
所以,在使用解析结果之前,需要先快速判断它是否真正“可用”。这件事不需要读源码、不需要跑benchmark,但需要知道看什么、怎么看。本文提供一套可操作的检查清单,并介绍一个能帮你同时对比多个解析方案差异的工具。

复杂表格样例 表格识别隐蔽结构错误
一、三个维度,一张表说清楚
判断表格解析质量,可以看三个层次:逻辑结构重建、语义关系映射、内容信息还原。这里不展开理论探讨,直接提供可操作的检查问题。

三层的检查成本依次递增:结构对不对一眼可见,关系对不对需要对比原文,内容对不对需要逐格核对。日常自查时,先看结构,再看关系,最后抽查内容。
二、结构对不对:一眼能看到的“变形”
结构是表格解析的第一关,这一层围绕四个问题展开:
1. 表格区域画对了吗?
解析结果里有没有多出不属于表格的内容?比如标题、页眉、印章被混入了表格。有没有少了本该属于表格的内容?比如表头注释被截断,或者一张完整的表格被切成了多块。
.png "image")
正确

错误
2. 行列数量对吗?
数一下原表有几行几列,再看输出结果的行列数。常见错误是多了一列(把空列也算进去)、少了一行(小计行漏掉)、一列被拆成两列。

正确

错误
3. 合并单元格还在吗?
原表里跨行或跨列的合并区域,在解析结果里是被还原为一个大格,还是被拆散成多个重复内容的小格?合并单元格通常表达的是分组关系,一旦被拆散,数据的业务归属就丢了。

正确
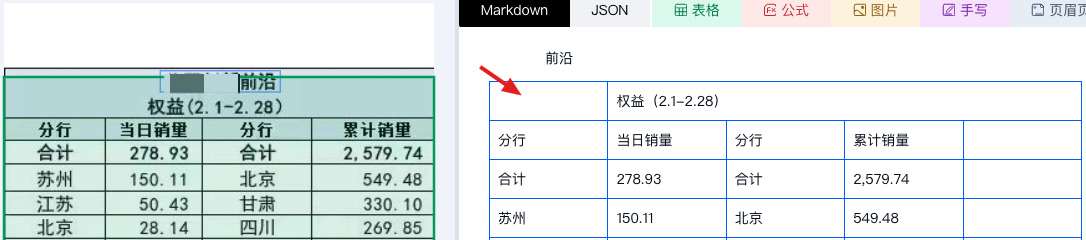
错误
4. 跨页表接上了吗?
如果原表跨了多页,解析结果是一张完整的表,还是被拆成多张独立表?续表是否继承了第一页的表头?跨页拼接错误常见于长清单、审计底稿、资产台账等场景。
如果有一项没通过,解析结果就不可用,后面的关系和内容检查可以先放一放。结构是表格解析的第一道门槛。
三、关系对不对:需要对比原文的“归属检查”
这一层更隐蔽,但直接影响数据的业务含义。关系自查不需要逐格做,抽检关键字段即可,如果抽检发现归属错误,就可以判断解析结果不可靠。
1. 表头和数据挂对了吗?
挑几个数据行,对应到原文,确认每个数值的列名归属是否正确。尤其关注多层表头——同一列名(如 Q2)是否挂到了正确的父表头下。一个典型例子:表格有“收入”和“成本”两个父表头,各自下挂 Q1、Q2 两列。如果解析结果把两组 Q2 拍平,某个 Q2 数值就分不清属于收入还是成本——这就是归属错误。
.png "image")
多层表格图例
2. 嵌套表格的父子关系还在吗?
如果原表某个单元格内嵌了子表(比如客户信息表里内嵌了订单明细)输出结果是保留了“主记录→子表”的层级结构,还是子表被拍平成了独立表格?父子关系一旦丢失,明细数据就成了无主数据。
3. 注释、单位、上下文还跟着表格吗?
原表上方的单位说明(如“单位:百万元”)、下方的注释是被保留并与表格主体关联,还是被当作独立段落甚至丢弃?缺少这些上下文,下游模型可能拿到正确的数字但做出错误的解读。
关系对,数据才有业务含义;关系错,再准确的数字也只是干扰项。这一层是验证“数据能不能直接用”的关键。

嵌套表格识别示例
四、内容对不对:必要时的精度抽查
内容层是最基础也最耗时的检查。对于大多数场景,如果结构和关系已经通过,内容错误属于低概率事件。不需要全表逐格核对,重点抽查以下高风险区域:
密集数字区域:小数点、负号、百分号是否丢失。密集小字表是这类错误的高发区,模型在分辨率不足时容易“猜”错数字。 小字或低对比度文字区域:扫描件里的浅色文字、表格底部的注释小字容易被漏掉。 手写或印章覆盖区域:手写内容压在表格线上、印章遮盖了关键数字,这类区域字符识别容易出错。
如果抽查未发现内容问题,这张表在内容层基本可用。如果发现多处问题,说明解析精度不达标,需要更换方案或引入人工复核。
五、比得太多看不过来?一个工具同时对比多个方案
以上三层自查清单,可以帮你系统性地判断一张表的解析结果是否可用。但实际操作中有一个明显的痛点:当你要对比多个解析方案时(例如开源方案 vs 云端 API),逐张表格按三层标准检查,工作量会成倍增加。
你需要在几个窗口之间来回切换原文、输出JSON、渲染结果,肉眼比对差异。每多一个方案,比对次数就呈指数增长。
xParse Playground的设计正是为了解决这个问题:上传一张复杂表格,同时看到不同解析方案的输出结果。差异高亮标注,结构错误、归属偏差、内容遗漏一目了然。
.png "image")

它不做价值判断,只做差异可视化。你已经知道怎么看了,现在可以用一个工具一次看完。
用你手头的复杂表格样本,去Playground看看不同方案的表现差距:https://www.textin.com/xparse/playground
📝总结
拿到表格解析结果后,按这三步快速自查:
先看结构:表格区域对不对、行列数对不对、合并单元格在不在、跨页表接没接上。结构不通过,直接打回。 再看关系:表头和数据是否挂对、嵌套表的父子关系是否保留、注释和单位是否还关联。关系不通过,数据不可信。 最后抽查内容:密集数字区、小字低对比度区、手写印章区,确认没有漏字错字。
自查是能力,工具是效率。当你需要同时对比多个解析方案时,Playground帮你在一个界面里快速完成这件事。带上你的样本里棘手的那张复杂表格,去真实测一次👇
https://www.textin.com/xparse/playground




