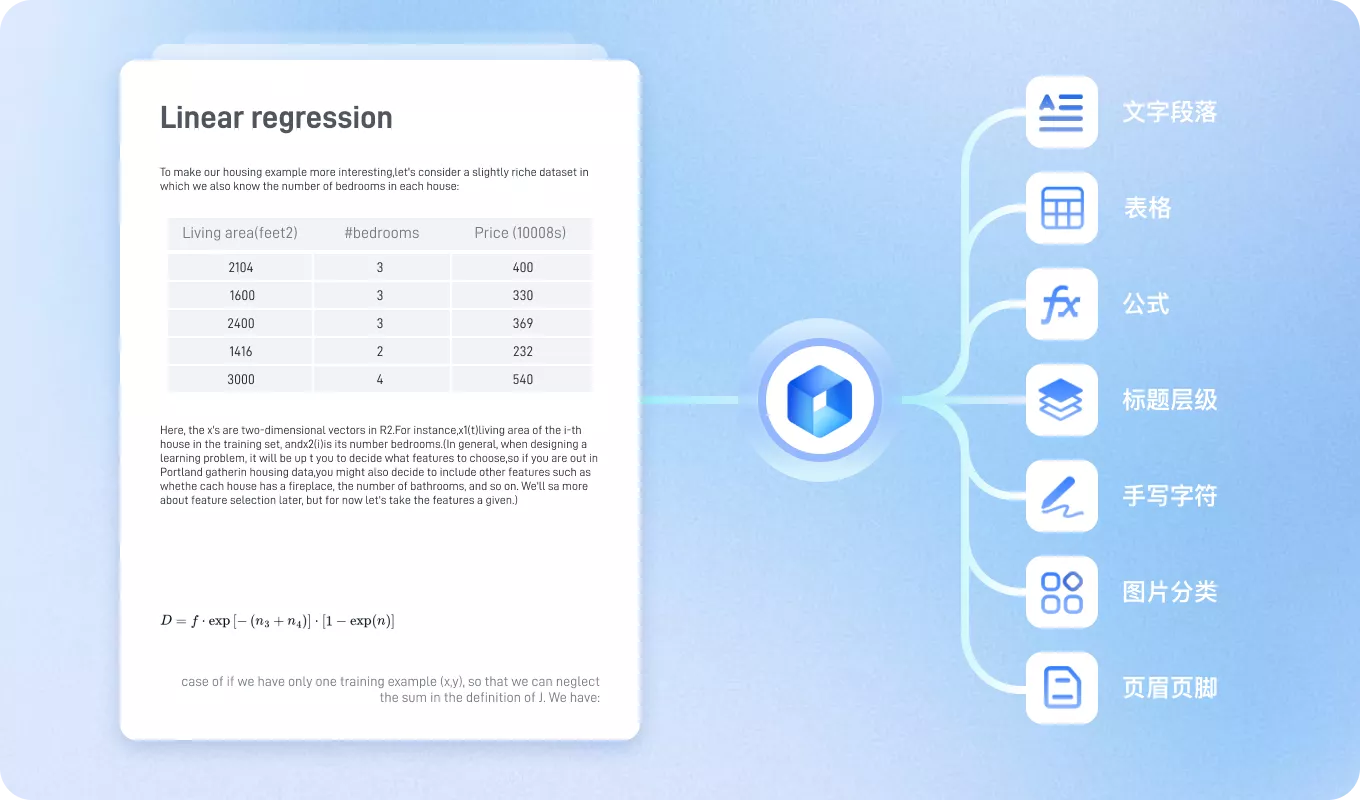
筑牢企业“智脑”数据底座
xParse 将海量 PDF、合同、研报等复杂文档转化为高质量结构化数据,助力企业高效构建知识库与 RAG 应用,支撑精准问答、知识检索与决策辅助。
适用于企业知识库构建RAG 前处理文档问答知识检索
深受全球1000+家领先企业的信赖
累计处理各类文档
1,000,000,000 +页
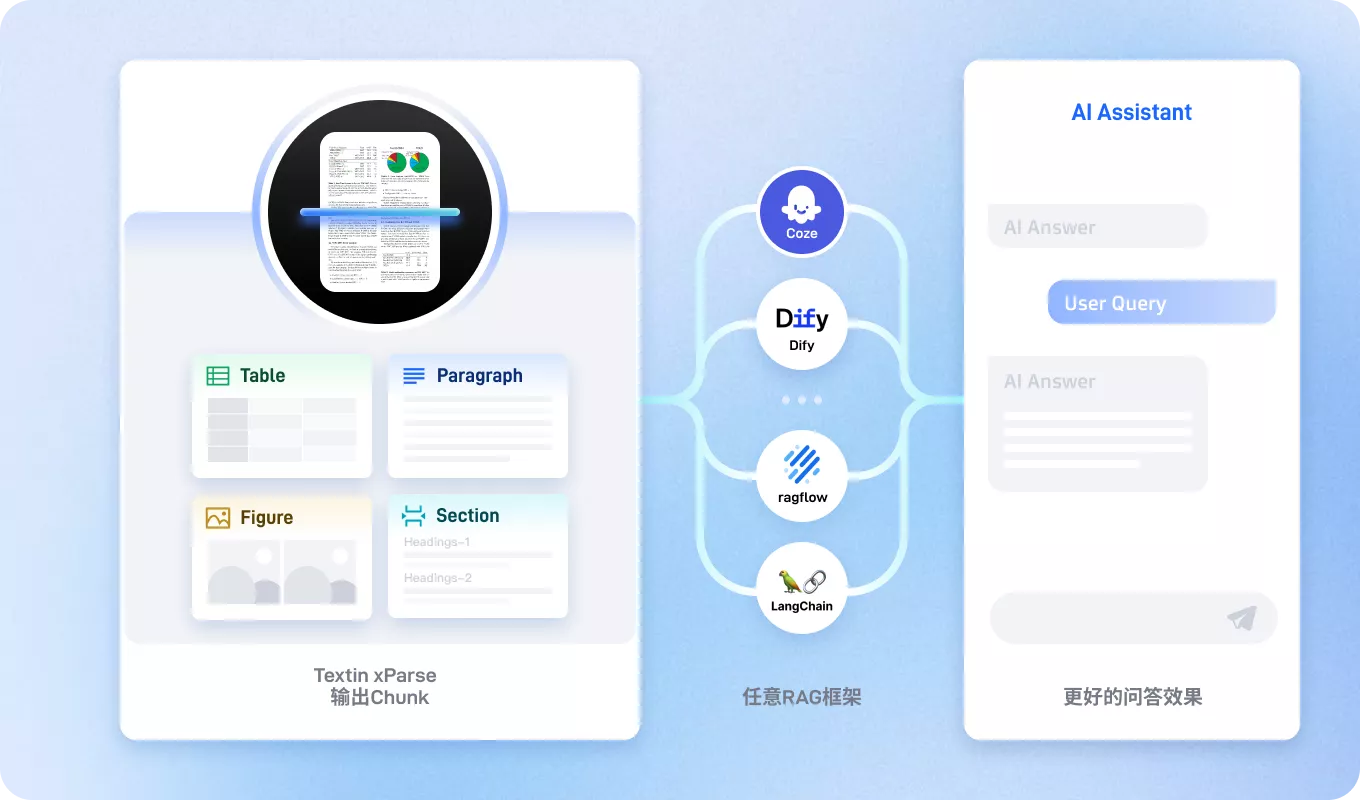
知识库 / RAG 场景下的典型应用
文档问答
支持基于合同、财报、教材、医学资料等复杂文档进行精准问答与来源追溯
适用场景
企业知识助手内部问答平台专业资料问答
知识检索
让复杂文档可切分、可索引、可检索,提升知识召回效果
适用场景
企业搜索内部资料检索研究资料查询
文档总结
支持长文档摘要、重点提炼、研究资料快速总结
适用场景
财报摘要政策总结论文提炼研报速读
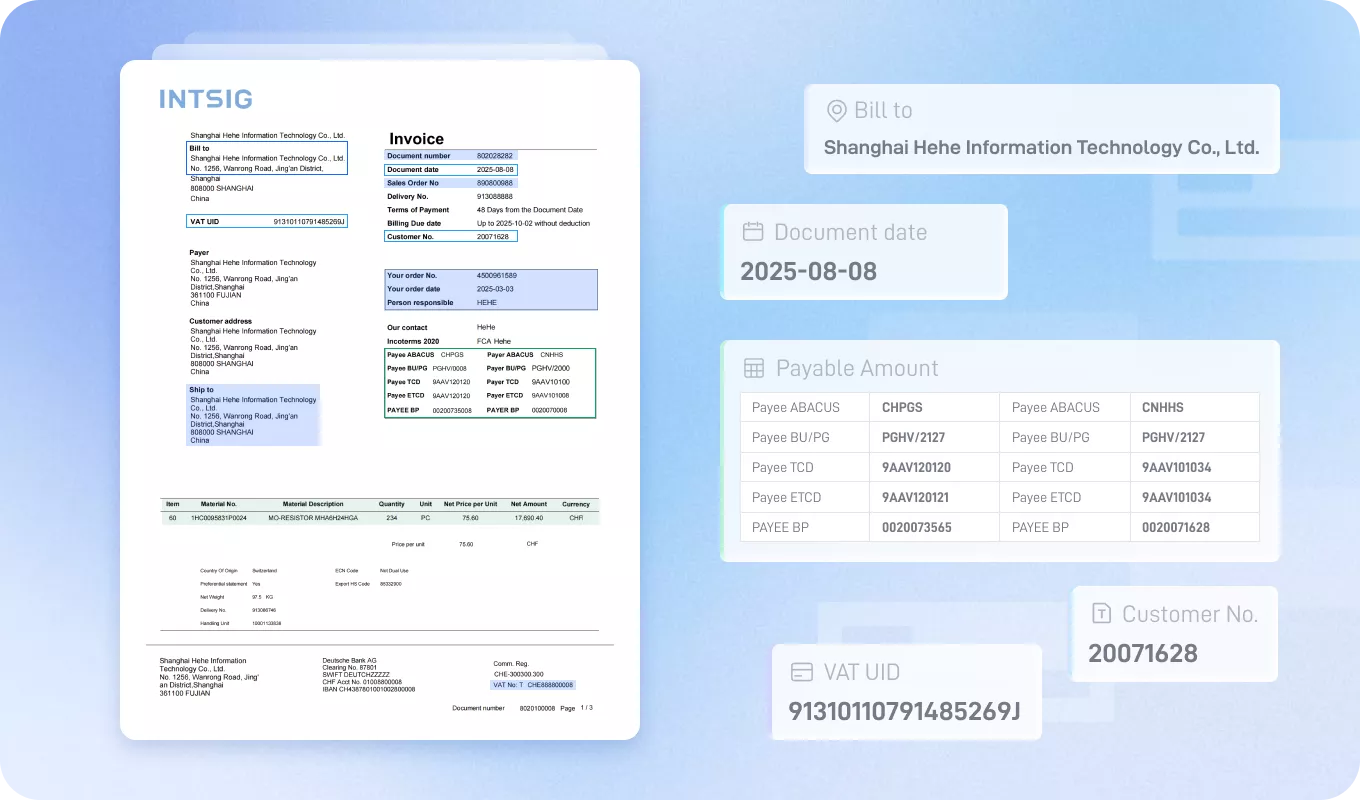
RAG 前处理
解决复杂 PDF、表格、目录、多栏版式解析难题,提升后续问答准确率
适用场景
知识库构建检索增强生成企业智能助手
知识库项目,为何常卡在第一步?
关键信息“沉睡”
海量合同、报告等文档无法被高效检索利用,关键信息长期闲置

预处理卡住知识库
文档清洗解析工作极重,知识库与RAG项目在启动阶段即受阻

RAG答非所问
因解析质量低下,RAG答案不准且结果缺乏可信来源佐证

知识迭代迟滞
新文档无法自动入库,知识库建成即过时,持续运营成本高昂

适合接入知识库 / RAG 的典型文档
研究与分析资料
财报研报公告行业报告
适合沉淀为企业研究知识库,支撑长期检索、问答与分析复用。
教学与科研资料
教材课件论文研究资料
适合构建教学知识库、科研资料库和学习检索系统,服务后续长期调用和内容沉淀。
制度与标准文件
政策标准SOP知识手册
适合沉淀为企业内部知识资产,支撑制度查询、员工问答与流程检索。
长期复用型法律资料
合同模板制度文件法律文书
适合纳入统一知识体系,支撑制度检索、法务知识管理和经验沉淀。
医学与专业知识资料
医学文献临床规范诊疗资料
适合构建专业知识库,为医疗知识服务和专业问答提供底座。
客户成功案例
来自全球1000+客户的信任与选择

医疗:和睦家医疗集团
挑战
传统OCR识别医疗数据效果不佳,大量内容需人工校对,成本很高,AI数字化建设进度缓慢。
解决方案
采用xParse私有化部署,支持集团大模型客户端知识库问答。
量化成果
90%+
信息提取准率
90%+
5倍效率
5倍效率提升,
让医生高效产出
6+场景
辅助临床决策、文献翻译、
快速写病历等6+场景

金融:某头部券商
挑战
投研、财富管理等多个业务线对公告、研报的智能问答需求迫切,但PDF文档结构复杂,传统解析效果差。
解决方案
xParse私有化部署,构建统一文档解析中台,服务投研、财富管理、风控等多个部门。
量化成果
POC满分
文档解析准确率
(尤其是复杂表格)
80%
知识检索与问答
效率提升80%
10+场景
支撑了智能投顾、研报撰写、
财报问答等10+个核心场景

教育:某知名SPOC高校教学平台
挑战
教学资料表格复杂,OCR丢失结构信息,导致知识库问答无法有效召回,拖慢平台答疑功能上线进程。
解决方案
采用xParse核心解析能力,为其SPOC平台与知识图谱提供高质量的结构化数据支持。
量化成果
95%+
教学资料关键信息提取
准确率95%+
85%+
复杂试题与大纲表格
解析率85%+
70%
平台知识库数据构建
效率提升70%
医疗:和睦家医疗集团
挑战
传统OCR识别医疗数据效果不佳,大量内容需人工校对,成本很高,AI数字化建设进度缓慢。
解决方案
采用xParse私有化部署,支持集团大模型客户端知识库问答。
量化成果
90%+
信息提取准率
90%+
5倍效率
5倍效率提升,
让医生高效产出
6+场景
辅助临床决策、文献翻译、
快速写病历等6+场景
金融:某头部券商
挑战
投研、财富管理等多个业务线对公告、研报的智能问答需求迫切,但PDF文档结构复杂,传统解析效果差。
解决方案
xParse私有化部署,构建统一文档解析中台,服务投研、财富管理、风控等多个部门。
量化成果
POC满分
文档解析准确率
(尤其是复杂表格)
80%
知识检索与问答
效率提升80%
10+场景
支撑了智能投顾、研报撰写、
财报问答等10+个核心场景
教育:某知名SPOC高校教学平台
挑战
教学资料表格复杂,OCR丢失结构信息,导致知识库问答无法有效召回,拖慢平台答疑功能上线进程。
解决方案
采用xParse核心解析能力,为其SPOC平台与知识图谱提供高质量的结构化数据支持。
量化成果
95%+
教学资料关键信息提取
准确率95%+
85%+
复杂试题与大纲表格
解析率85%+
70%
平台知识库数据构建
效率提升70%
为什么知识库 / RAG 场景更需要 xParse?

高质量Chunk奠定RAG基石
凭借在复杂表格、跨页标题等元素的卓越识别能力,我们的解析精度远超普通OCR方案,为RAG提供坚实基础。

企业级可靠服务
提供99.9%解析稳定率保障,支持公有云调用与私有化部署,满足金融、政务等场景对数据安全与合规的严苛要求。

开箱即用,无缝兼容
输出格式与LangChain、Dify、Coze等主流框架原生兼容,省去繁琐的数据预处理步骤,助您快速启动RAG应用开发。

端到端高效处理流水线
从文档解析、智能分块到向量化入库,提供自动化流水线,显著缩短知识库构建周期,提升迭代效率。

进一步查看知识库 / RAG 场景下的具体任务
根据不同文档类型和业务目标,继续查看更具体的解析任务与落地方案。

教材课件论文研究资料
教材知识库解析
面向教学资料知识库、科研资料沉淀和学习内容检索,提升教育类复杂文档的可用性。

政策标准SOP知识手册
制度 / 标准文件知识库解析
面向制度查询、流程检索和企业知识管理,帮助规范类文档进入统一知识系统。

合同法律文书制度文件
合同知识库解析
面向合同检索、法务知识管理和制度沉淀,帮助法律类文档实现长期复用。

财报公告分析报告
财报知识库解析
面向财报检索、研究资料沉淀和投研知识复用,提升复杂财务文档的结构化处理能力。

研报行业报告研究资料
研报知识库解析
面向研究资料入库、知识检索和分析复用,帮助高价值研究内容进入统一知识体系。
教材课件论文研究资料
教材知识库解析
面向教学资料知识库、科研资料沉淀和学习内容检索,提升教育类复杂文档的可用性。
政策标准SOP知识手册
制度 / 标准文件知识库解析
面向制度查询、流程检索和企业知识管理,帮助规范类文档进入统一知识系统。
合同法律文书制度文件
合同知识库解析
面向合同检索、法务知识管理和制度沉淀,帮助法律类文档实现长期复用。
财报公告分析报告
财报知识库解析
面向财报检索、研究资料沉淀和投研知识复用,提升复杂财务文档的结构化处理能力。
研报行业报告研究资料
研报知识库解析
面向研究资料入库、知识检索和分析复用,帮助高价值研究内容进入统一知识体系。
教材课件论文研究资料
教材知识库解析
面向教学资料知识库、科研资料沉淀和学习内容检索,提升教育类复杂文档的可用性。
知识库 / RAG 文档解析常见问题
01
为什么知识库 / RAG 场景需要专门的文档解析?
复杂 PDF 中的表格、多栏、目录、跨页标题和图片混排等内容,如果不能被正确识别和切分,会直接影响知识库的索引质量、检索召回和最终问答准确率。
02
xParse 适合接入哪些类型的知识库文档?
xParse 支持财报、研报、合同、教材、制度文件、医学资料、公告、行业报告等复杂文档,适合企业知识库、研究资料库、教学知识库和专业问答系统。
03
xParse 和普通 OCR 在知识库场景下有什么区别?
普通 OCR 更偏向文字识别,而知识库 / RAG 场景更关注文档结构、版式还原、表格解析、切分质量和后续检索效果。xParse 更适合输出可用于索引、问答和知识复用的结构化结果。
04
xParse 可以支持 RAG 前处理的哪些环节?
xParse 可用于复杂文档解析、结构化清洗、智能切分、Chunk 生成和入库前的数据准备,帮助提升知识库可用性和问答可信度。
05
哪些复杂文档更适合优先接入知识库?
通常包括财报、研报、合同、教材、制度文件、SOP、医学文献和长期复用型专业资料。这类文档价值高、复用周期长,更适合沉淀为可检索、可问答、可复用的知识资产。
立即启动您的高质量知识库项目
已有 1000+ 客户通过 TextIn 更好地拥抱LLM,进一步放大文档的价值
获取解决方案
体验解析能力


